Redis 实战系列(一)常用数据结构及使用场景总结
数据结构
Strings
| 单个 | 批量 | |
|---|---|---|
| 设值 | SET key value [NX | XX] [GET] [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | KEEPTTL]SETNX key valueSETEX key seconds valuePSETEX key milliseconds valueGETSET key valueSETRANGE key offset value |
MSET key value [key value …]MSETNX key value [key value …] |
| 取值 | GET keyGETDEL keyGETRANGE key start endSTRLEN key |
MGET key [key …] |
| 原子递增、递减 | INCR keyINCRBY key incrementINCRBYFLOAT key incrementDECR keyDECRBY key decrement |
|
| 追加 | APPEND key value |
|
| 位操作 | SETBIT key offset valueGETBIT key offsetBITCOUNT key [start end]BITOP operation destkey key [key …]BITFIELD …BITPOS key bit [start] [end] |
使用场景:
WEB 集群下的 Session 共享:
1
$ SET key value
分布式锁:
1
2
3
4
5
6
7
8# 返回 1 表示加锁成功,0 表示加锁失败
# 为了实现持锁人解锁(当前应用线程占有的锁不会被其它线程释放),可以将 value 参数设置为一个随机数,释放锁时先匹配随机数是否一致,一致再删除 key
$ SET key value EX 5 NX
# do something critical ...
# 解锁
$ DEL key全局计数器(例如 PV 统计):
1
2$ INCR key
$ DECR key分布式流水号:
1
2$ INCR key
$ INCRBY key
分布式流水号 Java 伪代码如下,单机一次性取 1000 个 ID,以降低网络开销和 Redis 负载:
1 | private int id; |
Hashes
散列表,一种通过散列函数计算对应数组下标,并通过下标随机访问数据时,时间复杂度为 O(1) 的特性快速定位数据的数据结构。Redis 散列表使用这种数据结构来快速获取指定 field。
| 单个 | 批量 | |
|---|---|---|
| 设置 field 的 value | HSET key field value [field value …]HSETNX key field value |
HMSET key field value [field value …] |
| 获取 field 的 value | HGET key fieldHSCAN key cursor [MATCH pattern] [COUNT count]HSTRLEN key field |
HMGET key field [field …] |
| 获取所有 fields | HKEYS key |
|
| 获取所有 values | HVALS key |
|
| 获取所有 fields 和 values | HGETALL key |
|
| 获取 field 的个数 | HLEN key |
|
| 判断 field 是否存在 | HEXISTS key field |
|
| 删除 field | HDEL key field [field …] |
|
| 原子递增、递减指定 field | HINCRBY key field incrementHINCRBYFLOAT key field increment |
Lists
双端队列。
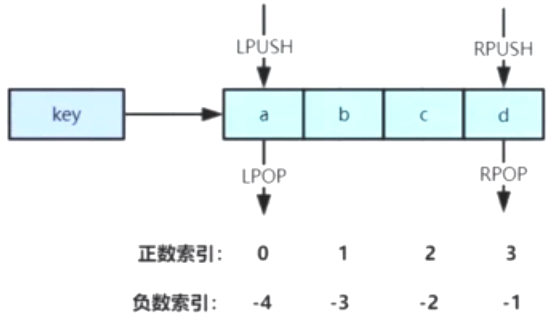
| 队列操作 | 左 | 右 |
|---|---|---|
| 入队 | LPUSH key element [element …]LPUSHX key element [element …] |
RPUSH key element [element …]RPUSHX key element [element …] |
| 出队 | LPOP key |
RPOP key |
| 阻塞出队 | BLPOP key [key …] timeout |
BRPOP key [key …] timeout |
| 插队 | LINSERT key BEFORE|AFTER pivot element |
|
| 获取指定索引的元素 | LINDEX key index |
|
| 获取指定范围的元素 | LRANGE key start stop |
|
| 获取列表长度 | LLEN key |
|
| 覆盖元素 | LSET key index element |
|
| 移除元素 | LREM key count element |
|
| 移除指定范围的元素 | LTRIM key start stop |
| 非阻塞 | 阻塞 | |
|---|---|---|
| 出队并重新入队另一个队列 | RPOPLPUSH source destination |
BRPOPLPUSH source destination timeout |
使用场景:
- Stack (FILO):
LPUSH+LPOP - Queue (FIFO):
LPUSH+RPOP,实现简单的消息队列 - Unbounded Blocking Queue (FIFO):
LPUSH+BRPOP
Sets
无序集合(散列表实现)。
集合操作:
| 集合操作 | 命令 |
|---|---|
| 添加元素(去重) | SADD key member [member …] |
| 移除元素 | SREM key member [member …] |
| 判断指定元素是否存在 | SISMEMBER key member |
| 获取元素个数 | SCARD key |
| 增量式遍历集合元素 | SSCAN key cursor [MATCH pattern] [COUNT count] |
| 获取所有元素 | SMEMBERS key |
| 获取指定个数的随机元素 | SRANDMEMBER key [count] |
| 移除指定个数的随机元素,并返回 | SPOP key [count] |
集合运算:
| 集合运算 | 数学符号 | 命令 |
|---|---|---|
| 移动指定元素到另一个集合 | SMOVE source destination member |
|
| 求交集(Intersection) | ∩ | SINTER key [key …] |
| 求交集(Intersection),并保存结果 | ∩ | SINTERSTORE destination key [key …] |
| 求并集(Union) | ∪ | SUNION key [key …] |
| 求并集(Union),并保存结果 | ∪ | SUNIONSTORE destination key [key …] |
| 求差集(Difference) | − | SDIFF key [key …] |
| 求差集(Difference),并保存结果 | − | SDIFFSTORE destination key [key …] |
使用场景:
UV 统计(缺点是随着用户量增长,会出现大 key。建议使用
HyperLogLog)抢红包、抽奖、秒杀 —— 本质上都是同一类问题,解决思路类似。为了减少对临界资源的竞争,避免使用各种锁进行并发控制,可以预先对临界资源进行拆分并加入到缓存,以提升性能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 预拆红包,放入集合
$ SADD key 子红包ID1 [子红包ID2 …]
# 查看所有红包
$ SMEMBERS key
# 随机抽取红包
$ SPOP key [count]
# 预先将奖品放入奖池
$ SADD key member [member …]
# 查看所有奖品
$ SMEMBERS key
# 随机抽奖(只抽一次)
$ SRANDMEMBER key [count]
# 登记参与抽奖的候选人
$ SADD key member [member …]
# 查看所有候选人
$ SMEMBERS key
# 随机抽取一二三等奖的获得者
$ SPOP key [count]社交应用的关注模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 我关注的人
$ SMEMBERS key
# 求共同关注
$ SINTER key [key ...]
# 我关注的人也关注 ta
foreach(member in 我_关注的人) {
# 我每个关注的人,他们关注的人中,是否有 ta
$ SISMEMBER member_关注的人 ta
}
# 我可能认识的人
foreach(member in 我_关注的人) {
# 我每个关注的人,他们关注的人中,有我还没关注的
$ SDIFF member_关注的人 我_关注的人
}商品筛选
1
2
3
4
5
6
7
8
9
10
11
12# 1、分类筛选维度,每个维度都为一个集合
# 2、将商品按维度加入所属集合
$ SADD key member
# 3、多选筛选条件时,求交集
$ SINTER key [key ...]
# 4、根据交集 member,获取商品详情(O(1) 时间复杂度)
foreach member {
# 每个 field 为商品属性
$ HGETALL member
}
Sorted Sets
有序集合(复合数据结构:散列表 + 跳表)。
集合操作:
| 集合操作 | 命令 |
|---|---|
| 添加元素 | ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member …] |
| 移除元素 | ZREM key member [member …] |
| 获取元素个数 | ZCARD key |
| 增量式遍历集合元素 | ZSCAN key cursor [MATCH pattern] [COUNT count] |
| 获取指定个数的随机元素 | ZRANDMEMBER key [count [WITHSCORES]] |
| 获取指定范围的元素(by index (rank), by the score, or by lexicographical order.) | ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES] |
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] |
|
ZRANGEBYLEX key min max [LIMIT offset count]ZREVRANGEBYLEX key max min [LIMIT offset count] |
|
| 移除指定个数的分值最高的元素,并返回 | ZPOPMAX key [count] |
| 移除指定个数的分值最低的元素,并返回 | ZPOPMIN key [count] |
使用场景:
Top K(例如排行榜)。实现思路:利用集合的三大特性之一——互异性,进行去重,相同元素只进行计数,形成一个二元组集合(key 为元素,value 为计数)。最后按计数结果对集合进行倒序排序,取前 N 个元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset -inf +inf BYSCORE LIMIT 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset +inf -inf BYSCORE REV LIMIT 0 -1
1) "three"
2) "two"
3) "one"
redis> ZRANGEBYSCORE myzset -inf +inf LIMIT 0 -1
1) "one"
2) "two"
3) "three"
redis> ZREVRANGEBYSCORE myzset +inf -inf LIMIT 0 -1
1) "three"
2) "two"
3) "one"
其它命令
| 命令 | |
|---|---|
| 删除 key | DEL |
| 设值 key 的过期时间(秒) | EXPIRE |