《证券投资基金》读书笔记——基金知识总结
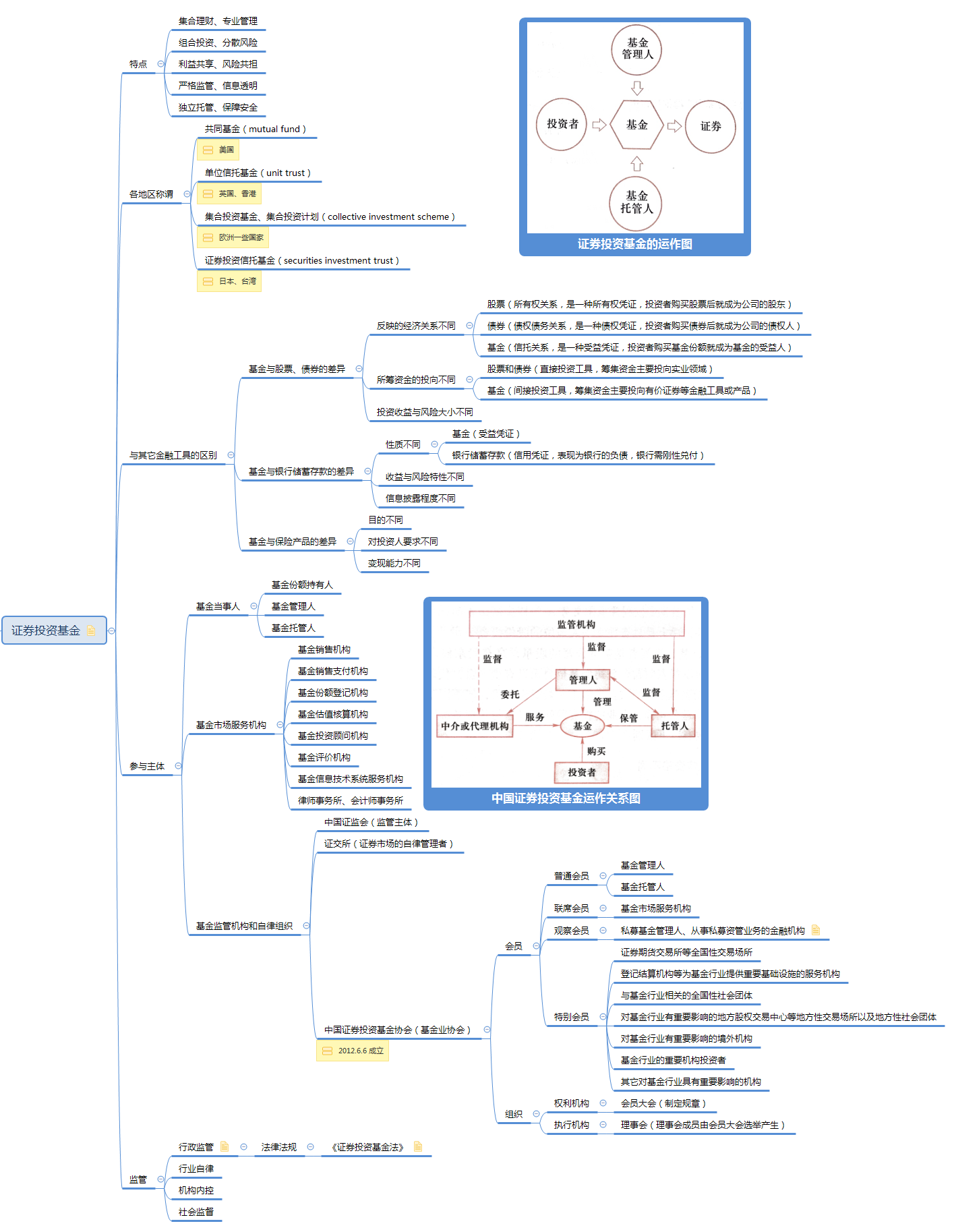
证券投资基金是资产管理的主要方式之一,它是一种组合投资、专业管理、利益共享、风险共担的集合投资方式。它主要通过向投资者发行受益凭证(基金份额),将众多不特定投资者的资金汇集起来,形成独立财产,委托基金管理人进行投资管理,基金托管人进行财产托管,由基金投资人共享投资收益、共担投资风险的集合投资方式。
投资基金是一种间接投资工具,基金投资者、基金管理人、托管人是基金运作中的主要当事人。
基金管理机构和托管机构分别作为基金管理人和基金托管人,一般按照基金的资产规模获得一定比例的管理费收入和托管费收入(即为净值型产品)。
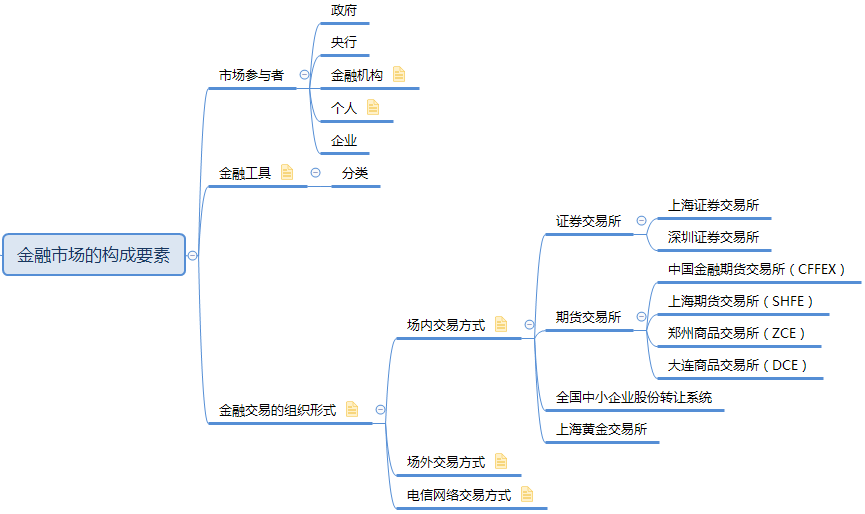
基金概况
基金分类
按法律形式
| 契约型基金 | 公司型基金 | |
|---|---|---|
| 法律主体资格不同 | 不具有法人资格 | 具有法人资格 |
| 投资者的地位不同 | 依据基金合同成立,基金投资者可通过持有人大会表达意见,但权利相对较小 | 通过股东大会,持有人权利较大 |
| 基金组织方式和营运依据不同 | 借用了信托法律制度,依据基金合同营运基金,基金投资人和基金管理人、托管人之间是信托委托人、受托人和受益人。基金投资人通过基金持有人大会行使权力。 | 借用了《公司法》规定的股份有限公司的组织方式,其依据投资公司章程营运基金,设有股东会、董事会等决策监督机构,基金投资人通过股东会行使权力,设立董事会进行相关事务的决策与监督,基金管理人的身份是公司董事会聘请的投资顾问。 |
| 优点 | 在设立上更为简单易行 | 法律关系明确清晰,监督约束机制较为完善 |
| 范围 | 中国的基金均是契约型基金 | 美国的投资公司为代表 |
按运作方式
| 开放式基金 | 封闭式基金 | |
|---|---|---|
| 份额 | 不固定 | 固定 |
| 存续期限 | 不确定,理论上可以无限期存续 | 确定 |
| 交易方式 | 一般不上市,通过向基金管理公司和代销机构进行申购、赎回 | 上市流通 |
| 交易价格 | 按照每日基金单位资产净值(NAVPS) | 根据市场行情变化,相对于单位资产净值可能折价或溢价,多为折价 |
| 估值频率 | 每个交易日估值,次日公告 | 每个交易日估值,每周披露 |
| 信息披露 | 每日公布基金单位资产净值(NAVPS),每季度公布资产组合,每六个月公布变更的招募说明书 | 每周公布基金单位资产净值(NAVPS),每季度公布资产组合 |
| 投资策略 | 强调流动性管理,基金资产中要保持一定现金及流动性资产 | 全部资金在封闭期内可进行长期投资 |
| 收益分配频率 | 开放式基金的基金合同应当约定每年基金收益分配的最多次数和基金收益分配的最低比例。实践中,许多基金合同规定每年至少一次。如果是货币基金,一般为每日结转收益或按月结转收益。 | 每年不得少于一次 |
| 收益分配方式 | 1、现金分红;2、分红再投资转换为基金份额 | 现金分红 |
| 总结 | 基金份额不固定,基金份额可以在基金合同约定的时间和场所进行申购、赎回的一种基金运作方式 | 基金份额在基金合同期限内固定不变,基金份额可以在证交所交易,但基金份额持有人不得申请赎回 |
按资金募集方式
| 公募基金 | 私募基金 | |
|---|---|---|
| 制度 | 基金募集注册制。即证监会不进行实质性审核,而只是进行合规性审查。 | 基金管理人登记制,即私募基金的基金管理人只需向基金业协会登记即可,无须中国证监会审批。 |
| 申请期限 | 依据《证券投资基金法》的规定,公募基金应当经中国证监会注册。证监会在受理申请之日起 6 个月内依照法律法规进行审查,作出注册或者不予注册的决定。 | 基金业协会应当在私募基金管理人登记材料齐备后的 20 个工作日内,通过网站公告私募基金管理人名单及其基本情况的方式,为私募基金管理人办理登记手续。 |
| 监管主体 | 由证监会监管 | 由基金业协会制定相关指引和准则,实行自律管理。 |
| 提交文件 | 1、申请报告;2、基金合同草案;3、基金托管协议草案;4、招募说明书草案;5、律所出具的法律意见书;6、中国证监会规定提交的其它文件。 | 1、工商登记和营业执照正副本复印件;2、公司章程或者合伙协议;3、主要股东或者合伙人名单;4、高级管理人员的基本信息;5、基金业协会规定的其它信息。 |
| 募集群体 | 不特定对象、或特定对象累计超过 200 人。 | 合格投资者,且累计不得超过 200 人。 |
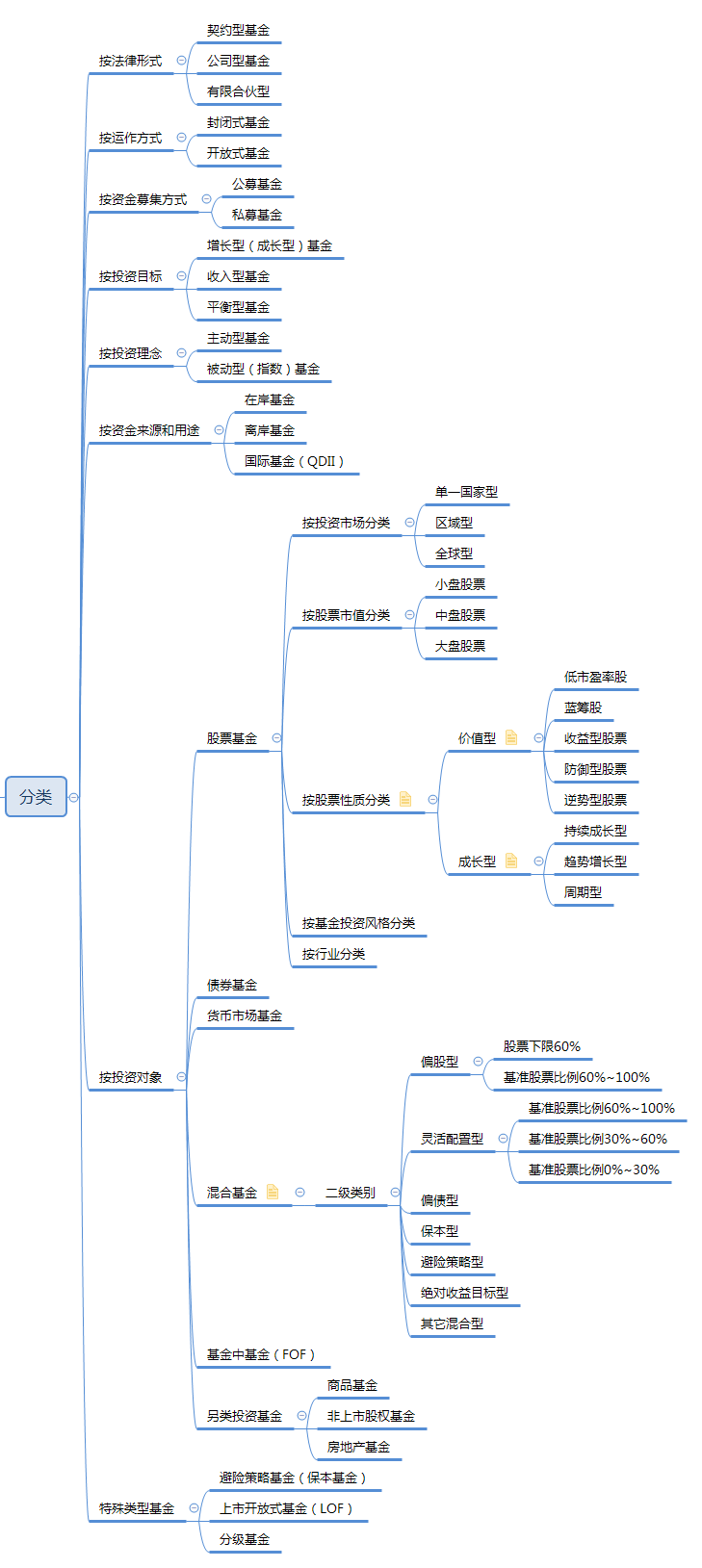
按投资对象
股票基金
债券基金
| 债券 | 债券基金 | |
|---|---|---|
| 利息 | 有固定的利息收入 | 不同债券的组合,利息不固定 |
| 到期日 | 有确定的到期日 | 没有确定的到期日 |
| 收益率 | 单一债券的收益率可以根据购买价格、现金流以及到期收回的本金计算其投资收益率 | 较难计算和预测收益率 |
| 投资风险 | 单一债券的信用风险比较集中,随着到期日的临近,所承担的利率风险会下降 | 债券基金通过分散投资可以有效避免单一债券可能面临的较高的信用风险。由于没有固定到期日,所承担的利率风险将取决于所持有的债券的平均到期日 |
债券基金的风险如下:
- 利率风险
- 再投资风险
- 信用风险
- 流动性风险
- 提前赎回风险
- 可转债的特定风险
- 债券回购风险
货币基金
货币市场基金在投资组合中的作用
与其它类型基金相比,货币市场基金具有风险低、流动性好的特点,是厌恶风险、对资产流动性和安全性要求较高的投资者进行短期投资和现金管理的理想工具,或是暂时存放现金的理想场所。
货币市场基金的投资对象与货币市场工具
货币市场基金的投资对象是货币市场工具,通常指到期日不足 1 年的短期金融工具,也成为现金投资工具。货币市场工具通常由政府、金融机构以及信誉卓著的大型工商企业发行,流动性好、安全性高,但其收益率与其它证券相比则非常低。货币市场与股票市场的一个主要区别是:货币市场进入门槛通常很高,在很大程度上限制了一般投资者的进入。此外,货币市场属于场外交易市场,交易主要由买卖双方通过电话或电子交易系统以协商价格完成。货币市场基金的投资门槛极低,因此,货币市场基金为普通投资者进入货币市场提供了重要通道。
按照中国证监会和中国人民银行 2015 年颁布的《货币市场基金监督管理办法》的规定,货币市场基金应当投资于以下金融工具:
- 现金;
- 期限在 1 年以内(含 1 年)的银行存款、债券回购、中央银行票据、同业存单;
- 剩余期限在 397 天以内(含 397 天)的债券、非金融企业债务融资工具、资产支持证券;
- 中国证监会、中国人民银行认可的其它具有良好流动性的货币市场工具。
货币市场基金不得投资于以下金融工具:
- 股票;
- 可转换债券、可交换债券;
- 以定期存款利率为基准利率的浮动利率债券,已进入最后一个利率调整期的除外;
- 信用等级在 AA+ 以下的债券与非金融企业债务融资工具;
- 中国证监会、中国人民银行禁止投资的其它金融工具。
货币市场基金的支付功能
由于货币市场基金风险低、流动性好,通过以下机制设计,基金管理公司将货币市场基金的功能从投资拓展为类似货币的支付功能:
- 每个交易日办理基金份额申购、赎回;
- 在基金合同中将收益分配的方式约定为红利再投资,并每日进行收益分配(每日结转收益);
- 每日按照面值(一般为 1 元)进行报价。
基金术语
基金分红
基金收益分配(即分红)是指将本基金的净收益根据持有基金单位的数量(即持有份额)按比例向基金持有人进行分配。若基金上一年度亏损,当年收益应先用于弥补上年亏损,在基金亏损完全弥补后尚有剩余的,方能进行当年收益分配。基金当年发生亏损无净收益的,不进行收益分配。
基金进行收益分配会导致基金份额净值的下降,但对投资者的利益没有实际影响。一只基金在收益分配前份额净值为1.2元,每份基金分配0.05元收益,在分配后基金份额净值将会下降到1.15元。但对投资者来说,分红前后的价值是不变的。
收益分配后基金份额净值不得低于面值。
现有制度下,基金分红主要有两种形式:
- 现金分红。是指直接获得现金红利,落袋为安;
- 红利再投资转换为基金份额。红利再投资是指将所分得的现金红利再投资该基金或者购买的个股,从而达到增加原先持有基金或股票的份额,俗称“利滚利”,这样做既可免掉再投资的申购费,而且再投资所获得的基金份额还可以享受或增加下次分红的数额,可使基金份额随着分红的次数而增加。
假如选择红利再投资方式对开放式基金进行长期投资,则可享受基金投资增值的复利增长效果。例如,假如开放式基金每年分红5%,选择红利再投资,则10年后资金将增值为62.89%;而假如同样的收益情况,选择现金分红方式,则10年后资金只增值为50%,收益少了12.89%。假如投资时间更长,则差别更大。
中国法律规定默认的基金分红方式是现金分红,投资者可以通过销售机构将分红方式变更为红利再投资,以获得更大的回报。
现金分红涉;及三个日期:
权益登记日:是基金公司进行红利分配时,需要定出某一天,界定哪些基金持有人可以参加分红,定出的这一天就是权益登记日。也就说,在权益登记日当天仍持有或申购基金并得到确认的投资者均可享受此次分红。
除息日:分红方案中确定的将红利从基金资产中扣除的日期。除息日当天,基金净值将会降低,如果不考虑当日市场波动,下降的幅度就是单位基金的现金分红额。
派息日:也就是基金分红拨付给基金持有人的日子。
基金分拆
基金分拆是指保证投资者的投资总额不发生改变的前提下,将一份基金按照一定的比例分拆为若干份,每一基金份额的单位净值也按相同比例降低:
- 分拆比例大于 1 的分拆为基金分拆;
- 分拆比例小于 1 的分拆为基金合并。
基金份额净值
- 基金资产估值:通过对基金所拥有的全部资产及全部负债按一定的原则和方法进行估算,进而确定基金资产公允价值的过程。
- 基金资产总值(AV, Asset Value):基金全部资产的价值总和。
- 基金资产净值(NAV, Net Asset Value):基金资产 - 基金负债(NAV = Assets - Liabilities)
- 基金份额净值(NAVPS, Net Asset Value Per Share):基金资产净值 / 基金总份额(NAVPS = Net Asset Value (NAV) / Number of Shares Outstanding)。也叫“单位净值”,与“累计净值”的区别查看这里。
- 基金份额:是指基金发起人向投资者公开发行的,表示持有人按其所持份额对基金财产享有收益分配权、清算后剩余财产取得权和其他相关权利,并承担相应义务的凭证。
一图看清“基金份额净值”:基金份额净值
基金份额类型(费率模式)
常见的基金收费有申购费、赎回费、管理费、托管费、销售服务费。还有一个认购费,但那是只有在基金募集期才会用到的。这么多费率,怎么区分?
货币基金
一般来说,我们常见的货币基金主要分A类、B类,其实货基的A、B类相差并不大,在收益方面的差别也不是很大,但门槛方面相差还是比较多的(具体以基金合同为准):
| 基金份额类型(费率模式) | 描述 |
|---|---|
| A类份额 | 货币基金中的低门槛份额,适用于认购、申购金额低于500万的投资者,散户投资者买货基都是此类; |
| B类份额 | 货币基金中的高门槛份额,适用于认购、申购金额高于500万的投资者,专为高净值客户或机构客户设置。 |
股票型/混合型/债券型基金
| 基金份额类型(费率模式) | 费用差别 | 适合人群 |
|---|---|---|
| A类份额 | 前端收费,即申购时收取申购费(不同的销售渠道会有打折) | 投资时间没有明确判断 |
| B类份额 | 后端收费,即赎回时收取申购费(持有的时间越长,申购费越少,持有超过一定年限后,不再收取) | 长期持有(一般3~5年) |
| C类份额 | 无申购费,但按日收取销售服务费 | 短期持有(一般1~2年) |
值得注意的是:A类份额和B类份额,都要收取一定的基金管理费和托管费,但是不收取销售服务费。
A类基金:前端申购费+赎回费+管理费+托管费
B类基金:后端申购费+赎回费+管理费+托管费
C类基金:销售服务费+赎回费+管理费+托管费
持有区间收益率
- 资产回报:是指股票、债券、房地产等资产价格的增加或减少。
- 资产回报率 = (期末资产价格 - 期初资产价格) ÷ 期初资产价格 × 100%
- 收入回报:包括分红、利息等。
- 收入回报率 = 期间收入 ÷ 期初资产价格 × 100%
- 持有区间收益 = 资产回报 + 收入回报
- 持有区间收益率 = 资产回报率 + 收入回报率
- 除权:因送股或配股而形成的剔除行为。
- 除息:因派息而引起的剔除行为。
- 除权(息)参考价 = (前收盘价 - 现金红利 + 配股价格 × 股份变动比例) ÷ (1+ 股份变动比例)
公式
申购计算公式
净申购金额=申购金额/(1+申购费率)
申购费用=申购金额-净申购金额
申购份额=净申购金额/T日基金份额净值











{kind=link}
{kind=link}