Jakarta EE 系列(三)Bean Validation 规范与实践总结
Bean Validation 规范
Bean Validation 为 JavaBean 和方法验证定义了一组元数据模型和 API 规范,常用于后端数据的声明式校验。
RoadMap
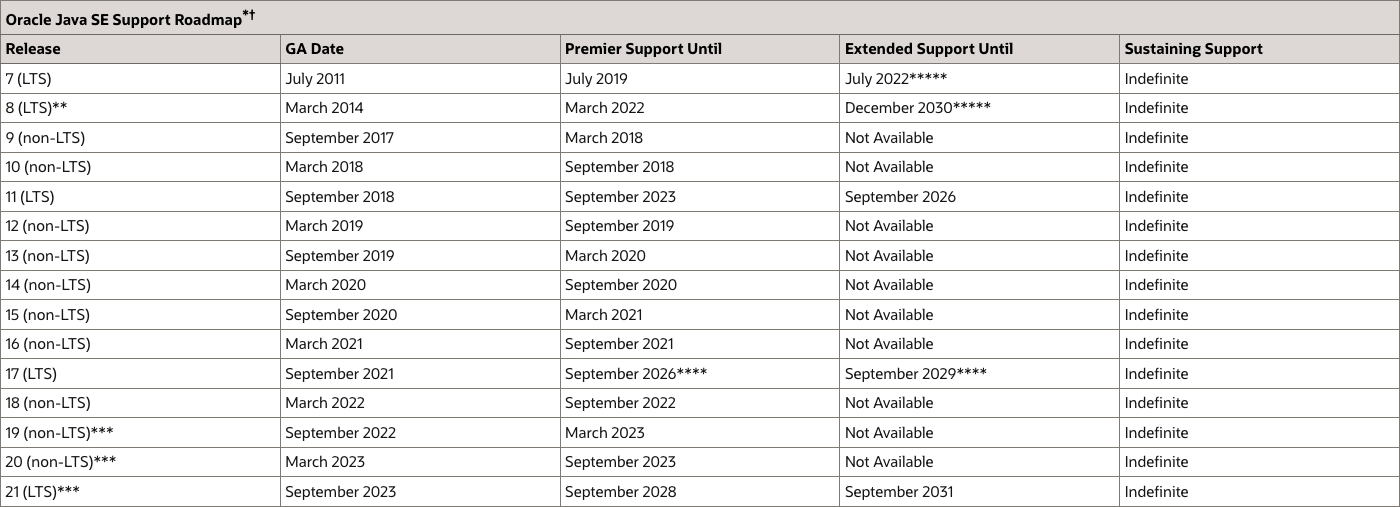
Bean Validation 规范最早在 Oracle Java EE 下维护。
2017 年 11 月,Oracle 将 Java EE 移交给 Eclipse 基金会。 2018 年 3 月 5 日,Eclipse 基金会宣布 Java EE (Enterprise Edition) 被更名为 Jakarta EE。因此 Bean Validation 规范经历了从 JavaEE Bean Validation 到 Jakarta Bean Validation 的两个阶段:
Bean Validation 1.0 (JSR 303)
Bean Validation 1.0 (JSR 303) was the first version of Java’s standard for object validation.
It was released in 2009 and is part of Java EE 6.
1 | <!-- https://mvnrepository.com/artifact/javax.validation/validation-api --> |
Bean Validation 1.1 (JSR 349)
Bean Validation 1.1 (JSR 349) was finished in 2013. Changes between Bean Validation 1.0 and 1.1
It is part of Java EE 7.
1 | <!-- https://mvnrepository.com/artifact/javax.validation/validation-api --> |
Bean Validation 2.0 (JSR 380)
Bean Validation 2.0 (JSR 380) was finished in August 2017. Changes between Bean Validation 2.0 and 1.1
It’s part of Java EE 8 (but can of course be used with plain Java SE as the previous releases).
1 | <!-- https://mvnrepository.com/artifact/javax.validation/validation-api --> |
Jakarta Bean Validation 2.0
Jakarta Bean Validation 2.0 was published in August 2019. There are no changes between Jakarta Bean Validation 2.0 and Bean Validation 2.0 except for the GAV: it is now
jakarta.validation:jakarta.validation-api.It’s part of Jakarta EE 8 (but can of course be used with plain Java SE as the previous releases).
1 | <!-- https://mvnrepository.com/artifact/jakarta.validation/jakarta.validation-api --> |
Jakarta Bean Validation 3.0
Jakarta Bean Validation 3.0 was released in Wednesday, October 7, 2020.
This release is part of Jakarta EE 9.
1 | <!-- https://mvnrepository.com/artifact/jakarta.validation/jakarta.validation-api --> |
Constraints
Constraints 约束是 Bean Validation 规范的核心。约束是通过约束注解和一系列约束验证实现的组合来定义的。约束注解可应用于类型、字段、方法、构造函数、参数、容器元素或其它约束注解。
一个 constraint 通常由 annotation 和相应的 constraint validator 组成,它们是一对多的关系。也就是说可以有多个 constraint validator 对应一个 annotation。在运行时,Bean Validation 框架本身会根据被注释元素的类型来选择合适的 constraint validator 对数据进行验证。
有些时候,在用户的应用中需要一些更复杂的 constraint。Bean Validation 提供扩展 constraint 的机制。可以通过两种方法去实现,一种是组合现有的 constraint 来生成一个更复杂的 constraint,另外一种是开发一个全新的 constraint。
下表列出了常用 Constraints:
内置 Constraints
表 1. Bean Validation 1.x 内置的 Constraints,如下:
| Constraint | 详细信息 |
|---|---|
@Null |
被注释的元素必须为 null |
@NotNull |
被注释的元素必须不为 null |
@AssertTrue |
被注释的元素必须为 true |
@AssertFalse |
被注释的元素必须为 false |
@Min(value) |
被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
@Max(value) |
被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
@DecimalMin(value) |
被注释的元素必须是一个数字,其值必须大于等于指定的最小值 |
@DecimalMax(value) |
被注释的元素必须是一个数字,其值必须小于等于指定的最大值 |
@Size(max, min) |
被注释的元素的大小必须在指定的范围内 |
@Digits (integer, fraction) |
被注释的元素必须是一个数字,其值必须在可接受的范围内 |
@Past |
被注释的元素必须是一个过去的日期 |
@Future |
被注释的元素必须是一个将来的日期 |
@Pattern(value) |
被注释的元素必须符合指定的正则表达式 |
Bean Validation 2.0 内置的 Constraints,参考:https://beanvalidation.org/2.0/spec/#builtinconstraints
Bean Validation 3.0 内置的 Constraints,参考官方新版规范:Jakarta Bean Validation specification
第三方 Constraints
表 2. Hibernate Validator 附加的 Constraints,更多 Constraints 详见:Additional constraints
| Constraint | 详细信息 |
|---|---|
@Email |
被注释的元素必须是电子邮箱地址 |
@Length |
被注释的字符串的大小必须在指定的范围内 |
@NotEmpty |
被注释的字符串的必须非空 |
@Range |
被注释的元素必须在合适的范围内 |
其它第三方 Constraints:
- Java Bean Validation Extension offers a set of useful constraints (
@Alphanumeric,@IPv6,@StartsWith…). - Collection Validators allows to define constraints on elements of collections.
- ……
核心 API
核心类 Validation 作为 Bean Validation 的入口点,提供了三种引导方式。下面代码演示了以最简单的方式创建默认的 ValidatorFactory,并获取 Validator 用以验证 Java Bean。涉及的 API 如下:
核心类
javax.validation.Validation:Note:
- The
ValidatorFactoryobject built by the bootstrap process should be cached and shared amongstValidatorconsumers. - This class is thread-safe.
- The
接口
javax.validation.ValidatorFactory:Factory returning initialized
Validatorinstances.Implementations are thread-safe and instances are typically cached and reused.
接口
javax.validation.Validator:Validates bean instances. Implementations of this interface must be thread-safe.
代码如下:
1 | import lombok.experimental.UtilityClass; |
Bean Validation 实现
Hibernate Validator
Hibernate 框架提供了各种子项目,如下:
其中,子项目 Hibernate Validator 是 Bean Validation 规范的官方认证实现。
要在 Maven 项目中使用 Hibernate Validator,需要添加如下依赖项:
新版实现。6.x 及以上版本已完全从 Hibernate 持久化框架中剥离并被移至新 group:
hibernate-validator is entirely separate from the persistence aspects of Hibernate. So, by adding it as a dependency, we’re not adding these persistence aspects into the project.
1
2
3
4
5
6<!-- https://mvnrepository.com/artifact/org.hibernate.validator/hibernate-validator -->
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
<version>7.0.0.Final</version>
</dependency>遗留实现,可以下载到 5.x 及之前的老版本,例如:
1
2
3
4
5
6<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-validator -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.4.3.Final</version>
</dependency>
下表汇总了 Hibernate Validator 各版本的传递依赖:
| Hibernate Validator | Java | Bean Validation 规范 | Expression Language (EL) 规范 |
|---|---|---|---|
| 7.0 series | 8, 11 or 17 | Jakarta EE 9 - Bean Validation 3.0 | Jakarta EE 9 - Expression Language 4.0 |
| 6.2 series | 8, 11 or 17 | Jakarta EE 8 - Bean Validation 2.0 | Jakarta EE 8 - Expression Language 3.0 |
| 6.1 series | 8, 11 or 17 | Jakarta EE 8 - Bean Validation 2.0 | Jakarta EE 8 - Expression Language 3.0 |
| 6.0 series | 8, 11 or 17 | JavaEE 8 - Bean Validation 2.0 (JSR 380) | Java EE 7 - Expression Language 3.0 (JSR 341) |
| 5.0 series | 6 or 7 | JavaEE 7 - Bean Validation 1.1 (JSR 349) | Java EE 7 - Expression Language 3.0 (JSR 341) |
引入 Hibernate Validator 后,将传递依赖 Bean Validation API 规范相应的版本,无需重复引入:
Hibernate’s Jakarta Bean Validation reference implementation. This transitively pulls in the dependency to the Bean Validation API.
详见如下
- https://search.maven.org/artifact/org.hibernate.validator/hibernate-validator
- /org/hibernate 该子项目 parent pom.xml 的版本号定义
使用方式
分组约束
如果我们想在新增的情况验证 id 和 name,而修改的情况验证 name 和 password,可以使用分组约束功能。
https://blog.csdn.net/win7system/article/details/51241837
组合约束
参考 Bean Validation 文档:Constraint composition
Constraint composition is useful in several ways:
- Avoid duplication and facilitate reuse of more primitive constraints.
- Expose primitive constraints as part of a composed constraint in the metadata API and enhance tool awareness.
Composition is done by annotating a constraint annotation with the composing constraint annotations.
compose constraints via a logical OR or NOT
参考 Hibernate 文档:Boolean composition of constraints
Jakarta Bean Validation specifies that the constraints of a composed constraint are all combined via a logical AND. This means all of the composing constraints need to return true to obtain an overall successful validation.
Hibernate Validator offers an extension to this and allows you to compose constraints via a logical OR or NOT. To do so, you have to use the
@ConstraintCompositionannotation and the enumCompositionTypewith its valuesAND,ORandALL_FALSE.
自定义约束
参考 Bean Validation 文档:Constraint validation implementation
Dubbo 参数验证
https://dubbo.apache.org/zh/docs/v2.7/user/examples/parameter-validation/
Spring MVC 参数验证
参考:
SpringBoot 中使用 @Valid 注解 + 全局异常处理器 优雅处理参数验证
@Valid由 Bean Validation 提供,由 Hibernate Validator 实现。@Validated由 Spring Validator 提供,是@Valid的变种,在使用上并没有区别,但在分组、注解位置、嵌套验证等功能上有所不同。
常见问题
缺少 Expression Language 依赖
以 Hibernate Validator 6.0 series 为例,查看其 pom.xml,会发现 Expression Language 依赖被声明为 provided:
1 | <dependency> |
这表示该依赖在运行时由 Java EE container 容器提供,因此无须重复引入。但对于 Spring Boot 应用来说,则需要添加此依赖。如果缺少该依赖,则报错如下:
1 | HV000183: Unable to load 'javax.el.ExpressionFactory'. Check that you have the EL dependencies on the classpath, or use ParameterMessageInterpolator instead |
问题原因:缺少 Unified Expression Language (EL) 规范的实现依赖,即 Glassfish。
解决方案:
Hibernate Validator also requires an implementation of the Unified Expression Language (JSR 341) for evaluating dynamic expressions in constraint violation messages.
When your application runs in a Java EE container such as WildFly, an EL implementation is already provided by the container.
In a Java SE environment, however, you have to add an implementation as dependency to your POM file. For instance, you can add the following dependency to use the JSR 341 reference implementation:
2
3
4
5
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.0</version>
</dependency>
注意,要使用与 Hibernate Validator 匹配的 Unified Expression Language (EL) 的依赖版本。
参考
https://docs.oracle.com/javaee/7/index.html
https://docs.oracle.com/javaee/7/api/index.html
https://jakarta.ee/specifications/bean-validation/
https://beanvalidation.org/2.0/spec/
http://hibernate.org/validator/
baeldung