// declare three objects (variables) of this type (product): apple, banana, and melon. structproduct { int weight; double price; } apple, banana, melon;
// struct requires either a type_name or at least one name in object_names, but not necessarily both. struct { int weight; double price; } apple, banana, melon;
// declare three objects (variables) of this type (product): apple, banana, and melon. product apple, banana, melon;
结构体数组
1 2
// because structures are types, they can also be used as the type of arrays. product banana[3];
结构体指针
1
product * p = &apple;
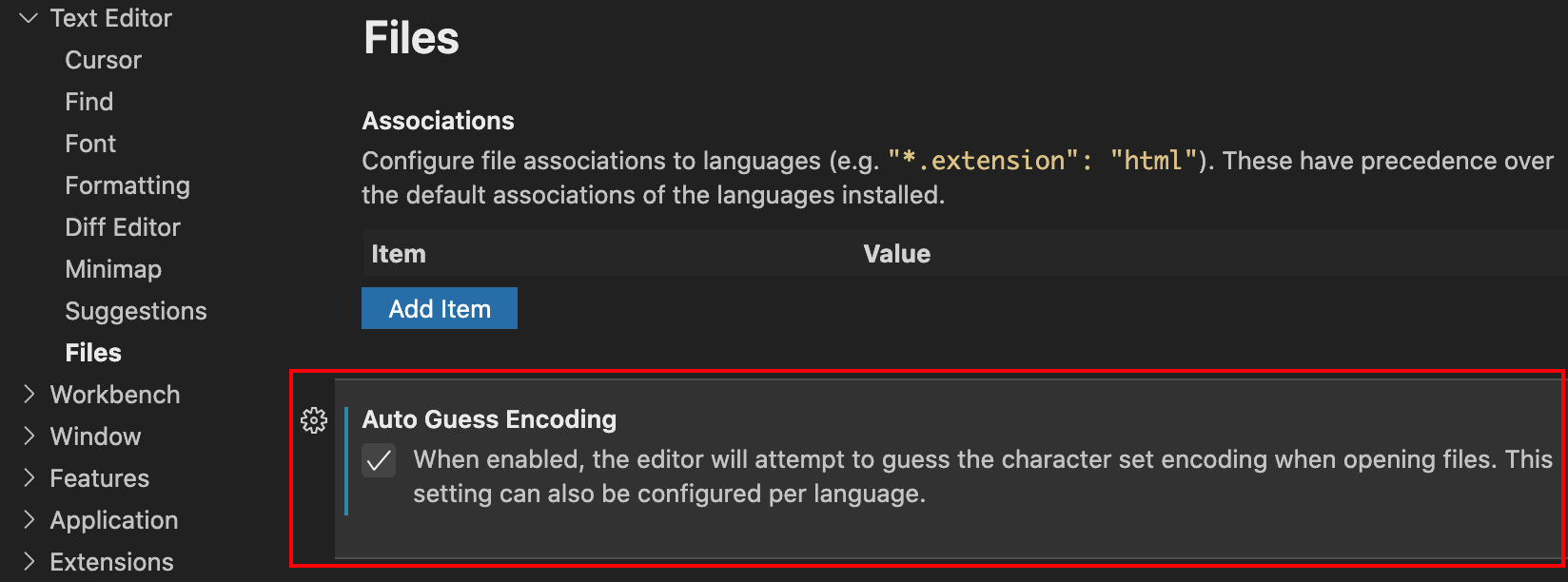
创建结构体指针之后,可以使用以下运算符访问其成员变量:
Operator
Expression
What is evaluated
Equivalent
dot operator (.)
a.b
Member b of object a
arrow operator (->) (dereference operator)
a->b
Member b of object pointed to by a
(*a).b
例子:
1 2 3 4 5
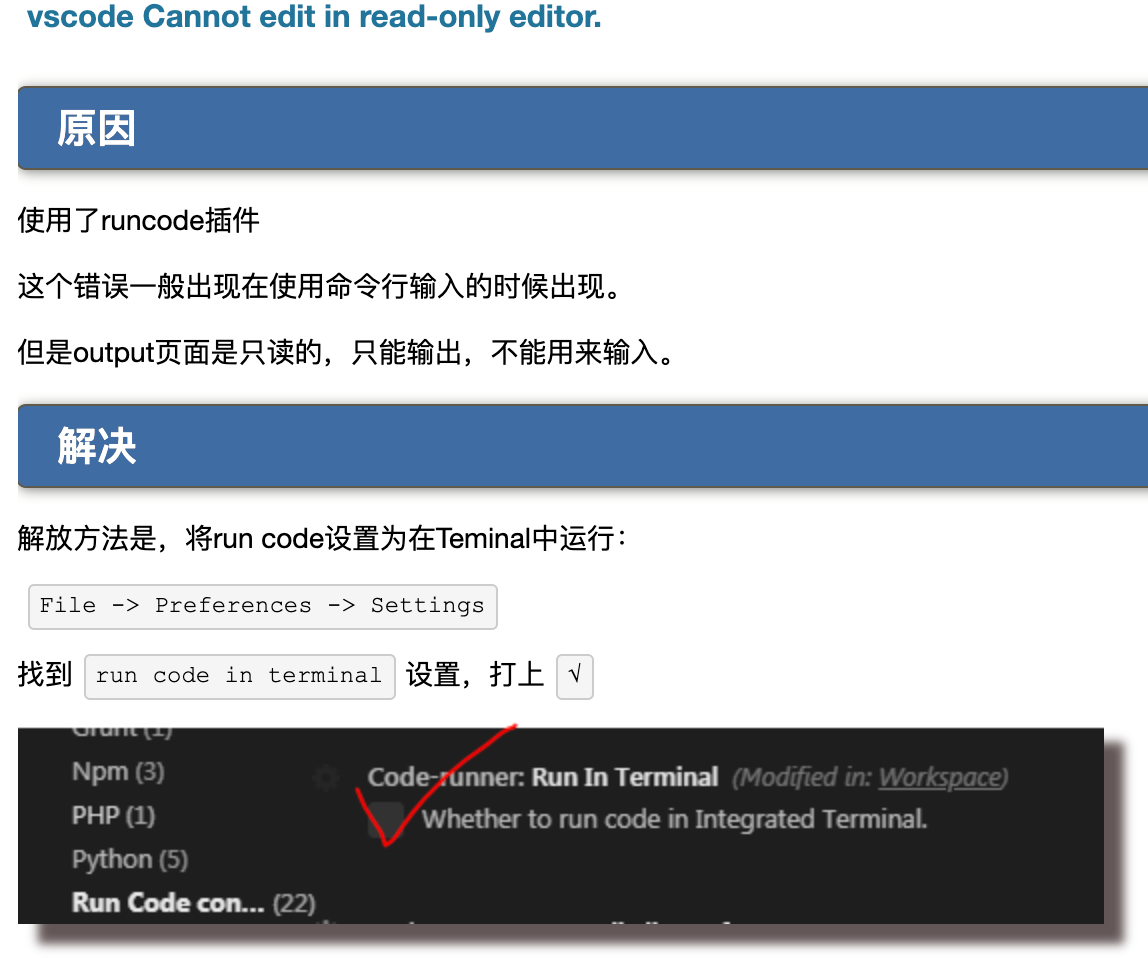
apple.weight; // 3 // The arrow operator (->) is a dereference operator that is used exclusively with pointers to objects that have members. This operator serves to access the member of an object directly from its address. p->weight; // 3 // equivalent to: (*p).weight; // 3
int arrayName[5] = {1, 2, 3, 4, 5}; // &arrayName = 0x7ffee7376620 int * p = arrayName; // // 数组指针(Pointers to array,即指向数组中第一个元素的地址)
for (int i = 0; i < 5; i++) { cout << p << endl; // 0x7ffee7376620 0x7ffee7376624 0x7ffee7376628 0x7ffee737662c 0x7ffee7376630 cout << *p++ << endl; // 1 2 3 4 5 }
结构体指针
1 2 3 4 5 6 7
product apple; // 结构体指针(Pointers to struct) product * p = &apple; // The arrow operator (->) is a dereference operator that is used exclusively with pointers to objects that have members. This operator serves to access the member of an object directly from its address. p->weight; // equivalent to: (*p).weight;
类指针
1 2 3 4 5 6 7 8 9 10
Rectangle rect(3, 4); // 类指针(Pointers to classes),主要用于多态性 Shape * p = ▭
// member y of object x rect.area(); // 12 // member y of object pointed to by x p->area(); // 12 // equivalent to: (*p).area(); // 12
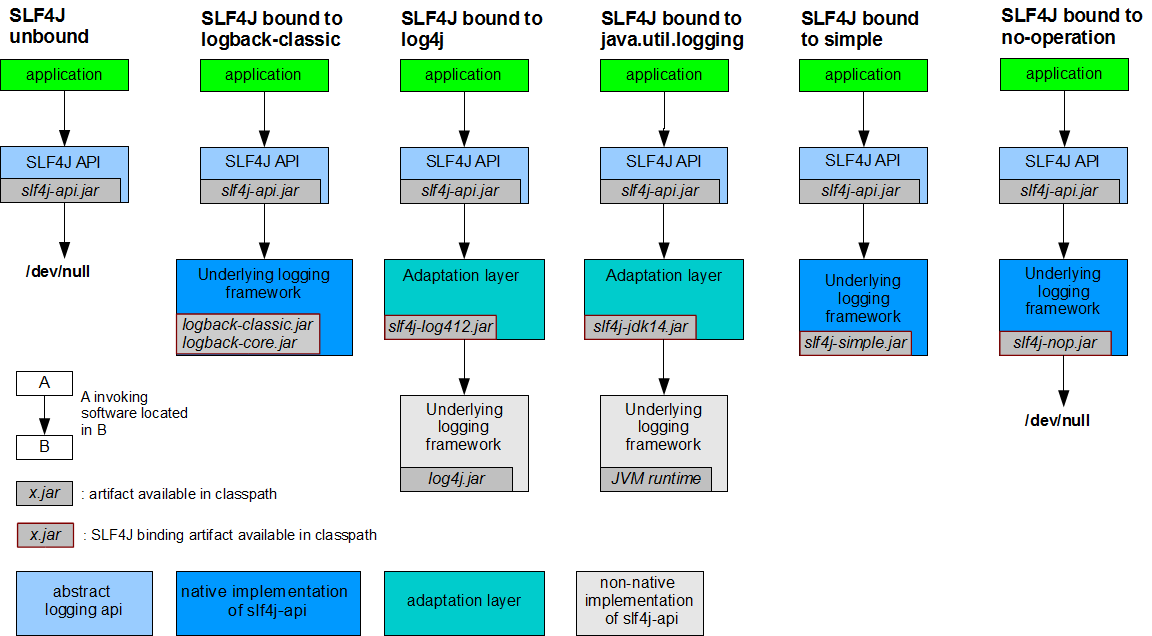
More visibly, slf4j-api now relies on the ServiceLoader mechanism to find its logging backend. SLF4J 1.7.x and earlier versions relied on the static binder mechanism which is no loger honored by slf4j-api version 2.0.x. More specifically, when initializing the LoggerFactory class will no longer search for the StaticLoggerBinder class on the class path.
Instead of “bindings” now org.slf4j.LoggerFactory searches for “providers”. These ship for example with slf4j-nop-2.0.x.jar, slf4j-simple-2.0.x.jar or slf4j-jdk14-2.0.x.jar.
To uniquely stamp each request, the user puts contextual information into the MDC, the abbreviation of Mapped Diagnostic Context.
The MDC class contains only static methods. It lets the developer place information in a diagnostic context that can be subsequently retrieved by certain logback components. The MDC manages contextual information on a per thread basis. Typically, while starting to service a new client request, the developer will insert pertinent contextual information, such as the client id, client’s IP address, request parameters etc. into the MDC. Logback components, if appropriately configured, will automatically include this information in each log entry.
Please note that MDC as implemented by logback-classic assumes that values are placed into the MDC with moderate frequency. Also note that a child thread does not automatically inherit a copy of the mapped diagnostic context of its parent.
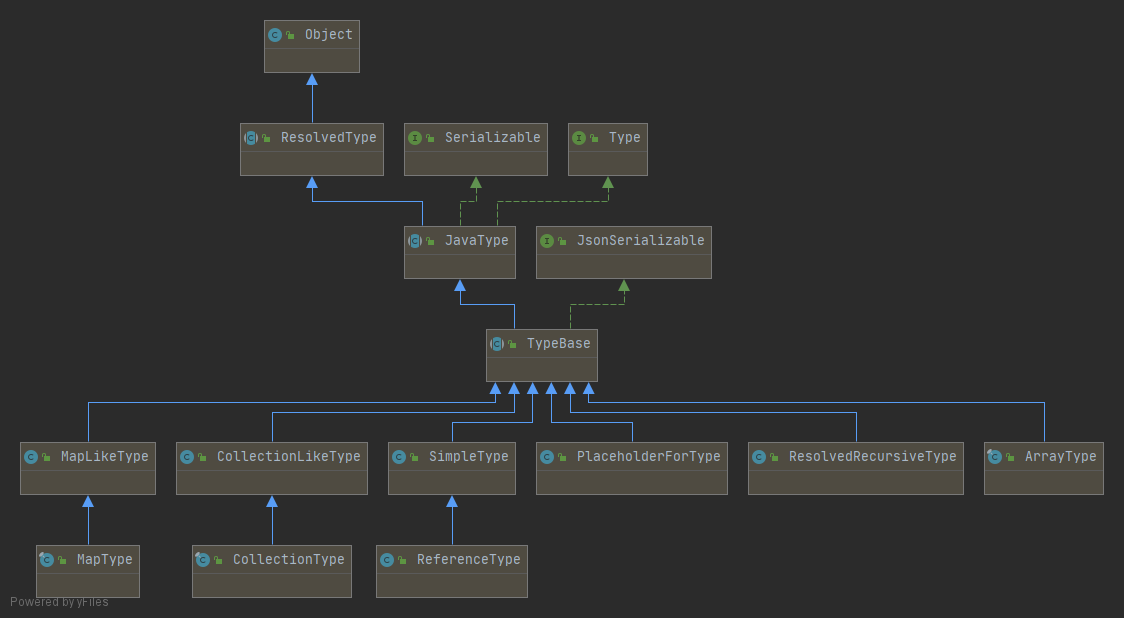
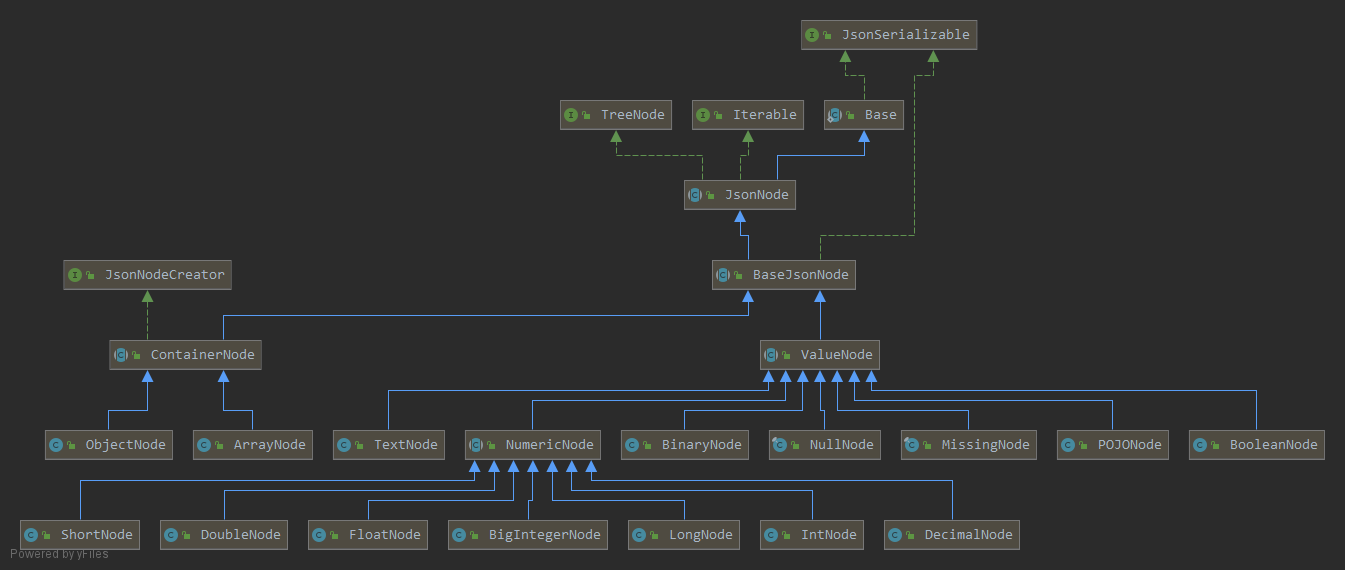
Core modules are the foundation on which extensions (modules) build upon. There are 3 such modules currently (as of Jackson 2.x):
Streaming (docs) (“jackson-core”) defines low-level streaming API, and includes JSON-specific implementations
Annotations (docs) (“jackson-annotations”) contains standard Jackson annotations
Databind (docs) (“jackson-databind”) implements data-binding (and object serialization) support on streaming package; it depends both on streaming and annotations packages
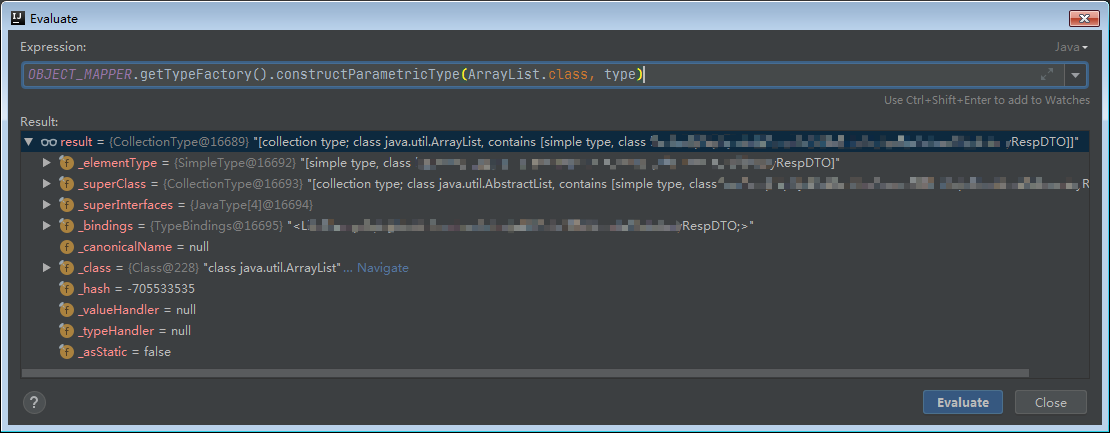
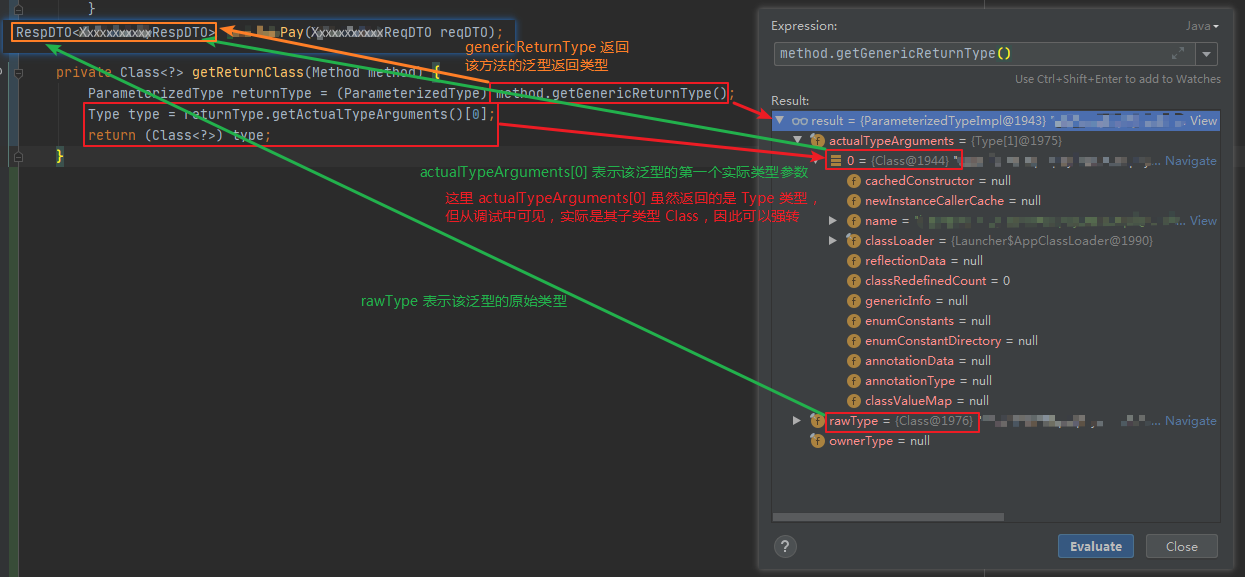
This generic abstract class is used for obtaining full generics type information by sub-classing; it must be converted to ResolvedType implementation (implemented by JavaType from “databind” bundle) to be used. Class is based on ideas from http://gafter.blogspot.com/2006/12/super-type-tokens.html, Additional idea (from a suggestion made in comments of the article) is to require bogus implementation of Comparable (any such generic interface would do, as long as it forces a method with generic type to be implemented). to ensure that a Type argument is indeed given.
Usage is by sub-classing: here is one way to instantiate reference to generic type List<Integer>:
1
TypeReference ref = new TypeReference<List<Integer>>() { };
which can be passed to methods that accept TypeReference, or resolved using TypeFactory to obtain ResolvedType.
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Cannot construct instance of `com.***.RespBody` (no Creators, like default construct, exist): cannot deserialize from Object value(no delegate- or property-based Creator)
解决方案:
POJO 加上 @NoArgsConstructor
Using Java inner classes for Jackson serialization