// 值比较 System.out.println(("a equals b is " + (a.equals(b)))); // a equals b is true
// 引用比较,结果为 false System.out.println("a == b is " + (a == b)); // a == b is false // 引用比较,结果意外的为 true。这是由于 Integer 自动装箱时 [-128, 127] 使用了缓存,详见其 valueOf 方法的源码实现。 System.out.println(("c == d is " + (c == d))); // c == d is true // 引用比较,结果为 false。因为 new Integer(int) 构造方法没有使用缓存。 System.out.println(("e == f is " + (e == f))); // e == f is false
/** * The value of the {@code Byte}. * * @serial */ privatefinalbyte value;
/** * Returns a {@code Byte} instance representing the specified * {@code byte} value. * If a new {@code Byte} instance is not required, this method * should generally be used in preference to the constructor * {@link #Byte(byte)}, as this method is likely to yield * significantly better space and time performance since * all byte values are cached. * * @param b a byte value. * @return a {@code Byte} instance representing {@code b}. * @since 1.5 */ publicstatic Byte valueOf(byte b) { finalintoffset=128; return ByteCache.cache[(int)b + offset]; }
/** * Returns the value of this {@code Byte} as a * {@code byte}. */ publicbytebyteValue() { return value; }
/** * Compares this object to the specified object. The result is * {@code true} if and only if the argument is not * {@code null} and is a {@code Byte} object that * contains the same {@code byte} value as this object. * * @param obj the object to compare with * @return {@code true} if the objects are the same; * {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Byte) { return value == ((Byte)obj).byteValue(); } returnfalse; } }
/** * The value of the {@code Short}. * * @serial */ privatefinalshort value;
/** * Returns a {@code Short} instance representing the specified * {@code short} value. * If a new {@code Short} instance is not required, this method * should generally be used in preference to the constructor * {@link #Short(short)}, as this method is likely to yield * significantly better space and time performance by caching * frequently requested values. * * This method will always cache values in the range -128 to 127, * inclusive, and may cache other values outside of this range. * * @param s a short value. * @return a {@code Short} instance representing {@code s}. * @since 1.5 */ publicstatic Short valueOf(short s) { finalintoffset=128; intsAsInt= s; if (sAsInt >= -128 && sAsInt <= 127) { // must cache return ShortCache.cache[sAsInt + offset]; } returnnewShort(s); }
/** * Returns the value of this {@code Short} as a * {@code short}. */ publicshortshortValue() { return value; }
/** * Compares this object to the specified object. The result is * {@code true} if and only if the argument is not * {@code null} and is a {@code Short} object that * contains the same {@code short} value as this object. * * @param obj the object to compare with * @return {@code true} if the objects are the same; * {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Short) { return value == ((Short)obj).shortValue(); } returnfalse; }
/** * The value of the {@code Integer}. * * @serial */ privatefinalint value;
/** * Returns an {@code Integer} instance representing the specified * {@code int} value. If a new {@code Integer} instance is not * required, this method should generally be used in preference to * the constructor {@link #Integer(int)}, as this method is likely * to yield significantly better space and time performance by * caching frequently requested values. * * This method will always cache values in the range -128 to 127, * inclusive, and may cache other values outside of this range. * * @param i an {@code int} value. * @return an {@code Integer} instance representing {@code i}. * @since 1.5 */ publicstatic Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; returnnewInteger(i); }
/** * Returns the value of this {@code Integer} as an * {@code int}. */ publicintintValue() { return value; }
/** * Compares this object to the specified object. The result is * {@code true} if and only if the argument is not * {@code null} and is an {@code Integer} object that * contains the same {@code int} value as this object. * * @param obj the object to compare with. * @return {@code true} if the objects are the same; * {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } returnfalse; }
/** * The value of the {@code Long}. * * @serial */ privatefinallong value;
/** * Returns a {@code Long} instance representing the specified * {@code long} value. * If a new {@code Long} instance is not required, this method * should generally be used in preference to the constructor * {@link #Long(long)}, as this method is likely to yield * significantly better space and time performance by caching * frequently requested values. * * Note that unlike the {@linkplain valueOf(int) * corresponding method} in the {@code Integer} class, this method * is <em>not</em> required to cache values within a particular * range. * * @param l a long value. * @return a {@code Long} instance representing {@code l}. * @since 1.5 */ publicstatic Long valueOf(long l) { finalintoffset=128; if (l >= -128 && l <= 127) { // will cache return LongCache.cache[(int)l + offset]; } returnnewLong(l); }
/** * Returns the value of this {@code Long} as a * {@code long} value. */ publiclonglongValue() { return value; }
/** * Compares this object to the specified object. The result is * {@code true} if and only if the argument is not * {@code null} and is a {@code Long} object that * contains the same {@code long} value as this object. * * @param obj the object to compare with. * @return {@code true} if the objects are the same; * {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Long) { return value == ((Long)obj).longValue(); } returnfalse; }
/** * The value of the Float. * * @serial */ privatefinalfloat value;
/** * Returns a {@code Float} instance representing the specified * {@code float} value. * If a new {@code Float} instance is not required, this method * should generally be used in preference to the constructor * {@link #Float(float)}, as this method is likely to yield * significantly better space and time performance by caching * frequently requested values. * * @param f a float value. * @return a {@code Float} instance representing {@code f}. * @since 1.5 */ publicstatic Float valueOf(float f) { returnnewFloat(f); }
/** * Compares this object against the specified object. The result * is {@code true} if and only if the argument is not * {@code null} and is a {@code Float} object that * represents a {@code float} with the same value as the * {@code float} represented by this object. For this * purpose, two {@code float} values are considered to be the * same if and only if the method {@link #floatToIntBits(float)} * returns the identical {@code int} value when applied to * each. * * <p>Note that in most cases, for two instances of class * {@code Float}, {@code f1} and {@code f2}, the value * of {@code f1.equals(f2)} is {@code true} if and only if * * <blockquote><pre> * f1.floatValue() == f2.floatValue() * </pre></blockquote> * * <p>also has the value {@code true}. However, there are two exceptions: * <ul> * <li>If {@code f1} and {@code f2} both represent * {@code Float.NaN}, then the {@code equals} method returns * {@code true}, even though {@code Float.NaN==Float.NaN} * has the value {@code false}. * <li>If {@code f1} represents {@code +0.0f} while * {@code f2} represents {@code -0.0f}, or vice * versa, the {@code equal} test has the value * {@code false}, even though {@code 0.0f==-0.0f} * has the value {@code true}. * </ul> * * This definition allows hash tables to operate properly. * * @param obj the object to be compared * @return {@code true} if the objects are the same; * {@code false} otherwise. * @see java.lang.floatToIntBits(float) */ publicbooleanequals(Object obj) { return (obj instanceof Float) && (floatToIntBits(((Float)obj).value) == floatToIntBits(value)); }
/** * The value of the Double. * * @serial */ privatefinaldouble value;
/** * Returns a {@code Double} instance representing the specified * {@code double} value. * If a new {@code Double} instance is not required, this method * should generally be used in preference to the constructor * {@link #Double(double)}, as this method is likely to yield * significantly better space and time performance by caching * frequently requested values. * * @param d a double value. * @return a {@code Double} instance representing {@code d}. * @since 1.5 */ publicstatic Double valueOf(double d) { returnnewDouble(d); }
/** * Compares this object against the specified object. The result * is {@code true} if and only if the argument is not * {@code null} and is a {@code Double} object that * represents a {@code double} that has the same value as the * {@code double} represented by this object. For this * purpose, two {@code double} values are considered to be * the same if and only if the method {@link * #doubleToLongBits(double)} returns the identical * {@code long} value when applied to each. * * <p>Note that in most cases, for two instances of class * {@code Double}, {@code d1} and {@code d2}, the * value of {@code d1.equals(d2)} is {@code true} if and * only if * * <blockquote> * {@code d1.doubleValue() == d2.doubleValue()} * </blockquote> * * <p>also has the value {@code true}. However, there are two * exceptions: * <ul> * <li>If {@code d1} and {@code d2} both represent * {@code Double.NaN}, then the {@code equals} method * returns {@code true}, even though * {@code Double.NaN==Double.NaN} has the value * {@code false}. * <li>If {@code d1} represents {@code +0.0} while * {@code d2} represents {@code -0.0}, or vice versa, * the {@code equal} test has the value {@code false}, * even though {@code +0.0==-0.0} has the value {@code true}. * </ul> * This definition allows hash tables to operate properly. * @param obj the object to compare with. * @return {@code true} if the objects are the same; * {@code false} otherwise. * @see java.lang.Double#doubleToLongBits(double) */ publicbooleanequals(Object obj) { return (obj instanceof Double) && (doubleToLongBits(((Double)obj).value) == doubleToLongBits(value)); }
/** * The value of the Boolean. * * @serial */ privatefinalboolean value;
/** * Returns a {@code Boolean} instance representing the specified * {@code boolean} value. If the specified {@code boolean} value * is {@code true}, this method returns {@code Boolean.TRUE}; * if it is {@code false}, this method returns {@code Boolean.FALSE}. * If a new {@code Boolean} instance is not required, this method * should generally be used in preference to the constructor * {@link #Boolean(boolean)}, as this method is likely to yield * significantly better space and time performance. * * @param b a boolean value. * @return a {@code Boolean} instance representing {@code b}. * @since 1.4 */ publicstatic Boolean valueOf(boolean b) { return (b ? TRUE : FALSE); }
/** * Returns the value of this {@code Boolean} object as a boolean * primitive. * * @return the primitive {@code boolean} value of this object. */ publicbooleanbooleanValue() { return value; }
/** * Returns {@code true} if and only if the argument is not * {@code null} and is a {@code Boolean} object that * represents the same {@code boolean} value as this object. * * @param obj the object to compare with. * @return {@code true} if the Boolean objects represent the * same value; {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Boolean) { return value == ((Boolean)obj).booleanValue(); } returnfalse; }
/** * The value of the {@code Character}. * * @serial */ privatefinalchar value;
/** * Returns a <tt>Character</tt> instance representing the specified * <tt>char</tt> value. * If a new <tt>Character</tt> instance is not required, this method * should generally be used in preference to the constructor * {@link #Character(char)}, as this method is likely to yield * significantly better space and time performance by caching * frequently requested values. * * This method will always cache values in the range {@code * '\u005Cu0000'} to {@code '\u005Cu007F'}, inclusive, and may * cache other values outside of this range. * * @param c a char value. * @return a <tt>Character</tt> instance representing <tt>c</tt>. * @since 1.5 */ publicstatic Character valueOf(char c) { if (c <= 127) { // must cache return CharacterCache.cache[(int)c]; } returnnewCharacter(c); }
/** * Returns the value of this {@code Character} object. * @return the primitive {@code char} value represented by * this object. */ publiccharcharValue() { return value; }
/** * Compares this object against the specified object. * The result is {@code true} if and only if the argument is not * {@code null} and is a {@code Character} object that * represents the same {@code char} value as this object. * * @param obj the object to compare with. * @return {@code true} if the objects are the same; * {@code false} otherwise. */ publicbooleanequals(Object obj) { if (obj instanceof Character) { return value == ((Character)obj).charValue(); } returnfalse; }
If you are inserting many rows from the same client at the same time, use INSERT statements with multiple VALUES lists to insert several rows at a time. This is considerably faster (many times faster in some cases) than using separate single-row INSERT statements.
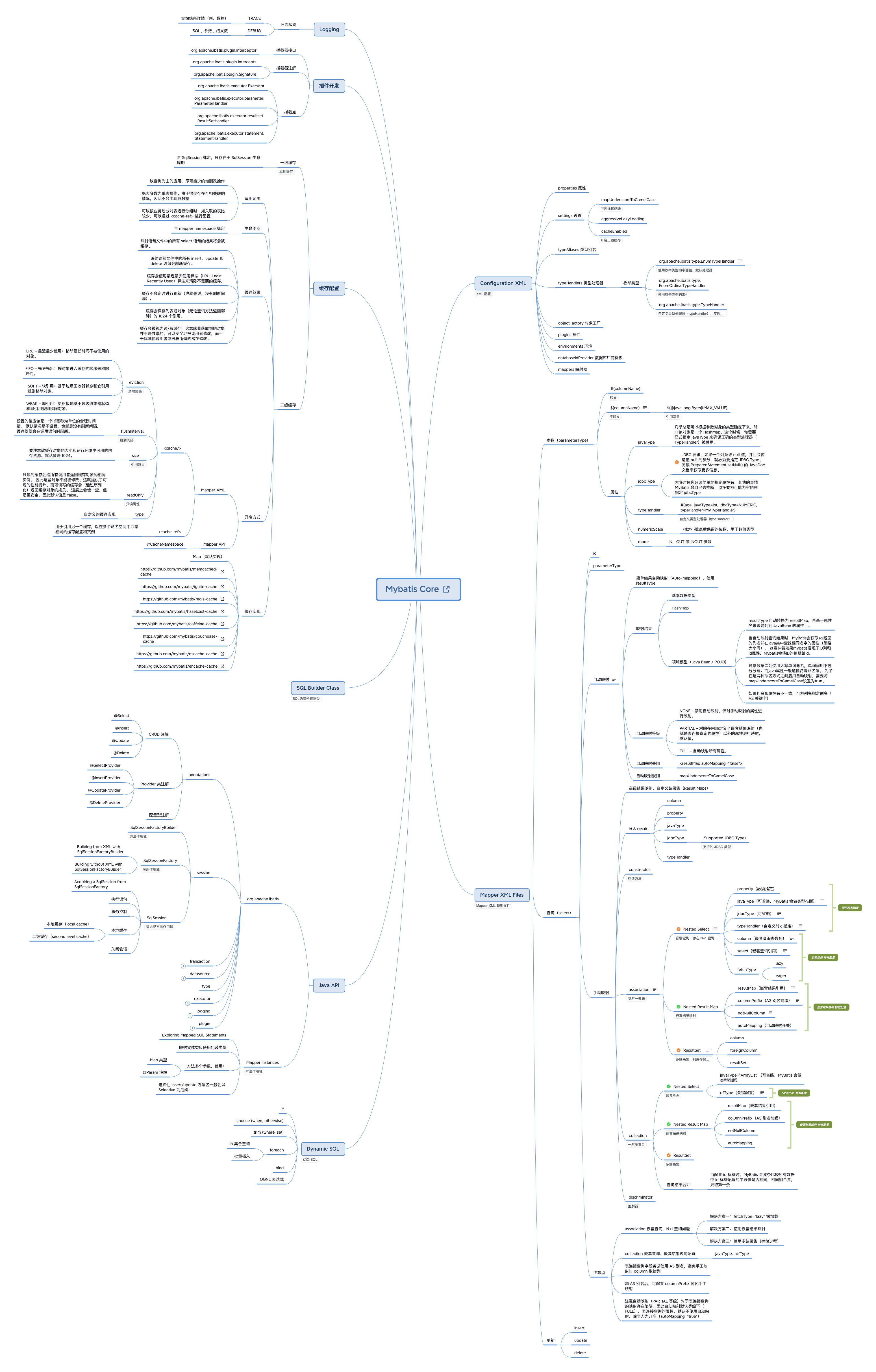
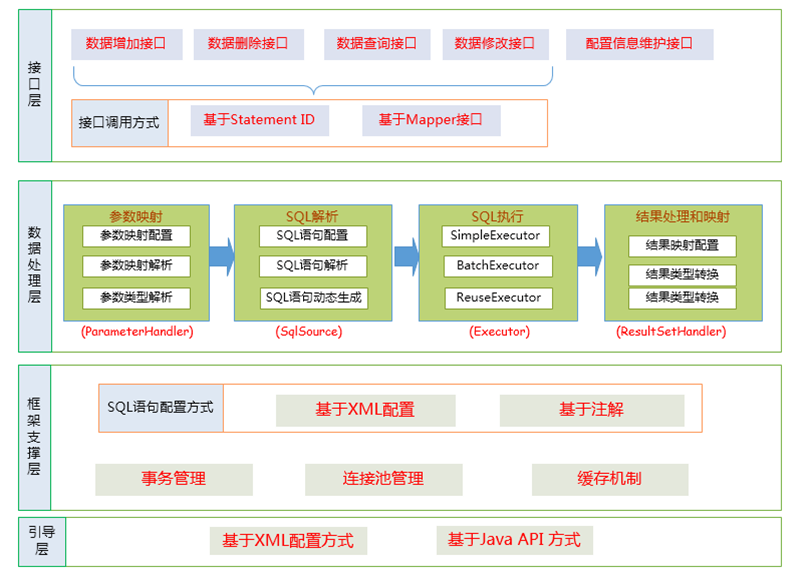
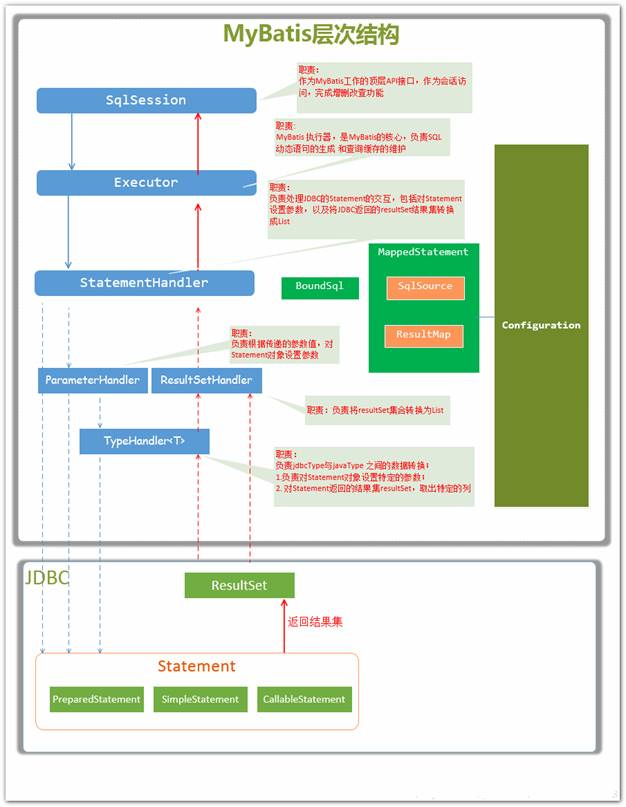
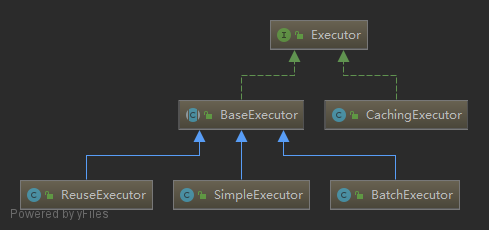
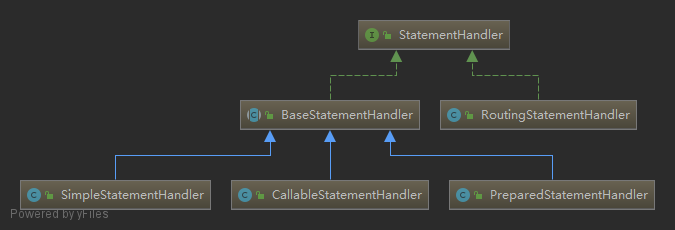
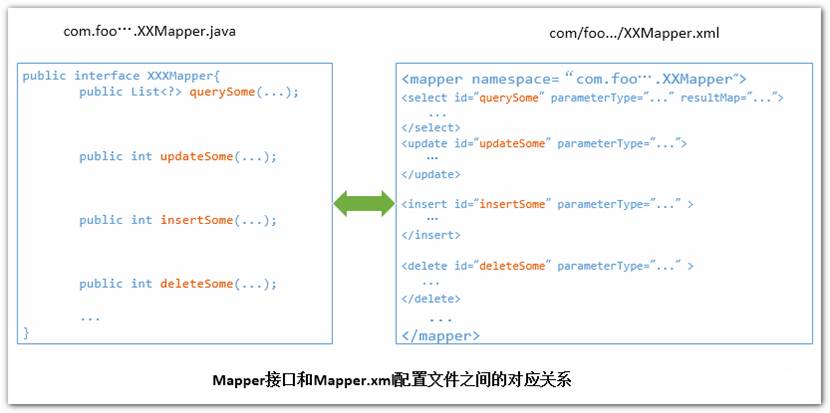
Whenever MyBatis sets a parameter on a PreparedStatement or retrieves a value from a ResultSet, a TypeHandler is used to retrieve the value in a means appropriate to the Java type.
When you are dealing with a constructor with many parameters, maintaining the order of arg elements is error-prone.
Since 3.4.3, by specifying the name of each parameter, you can write arg elements in any order. To reference constructor parameters by their names, you can
either add @Param annotation to them
or compile the project with ‘-parameters‘ compiler option and enable useActualParamName (this option is enabled by default).
javaType can be omitted if there is a property with the same name and type.
注意,如果抛出异常如下:
1
org.apache.ibatis.executor.ExecutorException: No constructor found in ...
解决方案:
如果是可变类(mutable classes),为类添加无参构造方法。
如果是不可变类(immutable classes),Mapper XML 结果映射 resultMap 必须使用正确参数的 constructor。
嵌套结果映射
两种嵌套关系配置:
association “has-one” type relationship
collection “has many” type relationship
两种查询方式:
嵌套查询(Nested Select),即分开多次查询。
嵌套结果映射(Nested Results),即利用表连接语法进行一次性的连表查询;
The association element deals with a “has-one” type relationship. For example, in our example, a Blog has one Author. An association mapping works mostly like any other result. You specify the target property, the javaType of the property (which MyBatis can figure out most of the time), the jdbcType if necessary and a typeHandler if you want to override the retrieval of the result values.
Where the association differs is that you need to tell MyBatis how to load the association. MyBatis can do so in two different ways:
Nested Select: By executing another mapped SQL statement that returns the complex type desired.
Nested Results: By using nested result mappings to deal with repeating subsets of joined results.
总结:
嵌套查询(Nested Select)
嵌套结果映射(Nested Results)
association 多对一关联
禁用
可用
collection 一对多关联
可用
可用
association 多对一关联,嵌套查询(Nested Select)存在 N+1 次查询的性能问题,不建议使用。
While this approach Nested Select is simple, it will not perform well for large data sets or lists. This problem is known as the “N+1 Selects Problem”. In a nutshell, the N+1 selects problem is caused like this:
You execute a single SQL statement to retrieve a list of records (the “+1”).
For each record returned, you execute a select statement to load details for each (the “N”).
This problem could result in hundreds or thousands of SQL statements to be executed. This is not always desirable.
The upside is that MyBatis can lazy load such queries, thus you might be spared the cost of these statements all at once. However, if you load such a list and then immediately iterate through it to access the nested data, you will invoke all of the lazy loads, and thus performance could be very bad.
<!-- 使用表连接嵌套查询学生、学校 --> <selectid="listStudents"resultMap="ExtendResultMap"> SELECT <includerefid="Extend_column_list" /> FROM t_student T INNER JOIN t_school E ON T.school_no = E.school_no WHERE T.age = #{age} </select>
SchoolMapper.xml
1 2 3 4 5 6 7 8 9 10 11 12 13
<sqlid="Base_Column_List"> E.id AS school_id, ...... E.create_time AS school_create_time, E.update_time AS school_update_time </sql>
MyBatis 回写主键利用了 JDBC 的特性,适用于支持自动生成主键的数据库,比如 MySQL 和 SQL Server。
First, if your database supports auto-generated key fields (e.g. MySQL and SQL Server), then you can simply set useGeneratedKeys="true" and set the keyProperty to the target property and you’re done.
1 2 3 4
<insertid="insertAuthor"useGeneratedKeys="true"keyProperty="id"> insert into Author (username,password,email,bio) values (#{username},#{password},#{email},#{bio}) </insert>
keyProperty attribute:
(insert and update only) Identifies a property into which MyBatis will set the key value returned by getGeneratedKeys, or by a selectKey child element of the insert statement. Default: unset.
自定义生成主键
适用于不支持自动生成主键的数据库,比如 Oracle。
MyBatis has another way to deal with key generation for databases that don’t support auto-generated column types, or perhaps don’t yet support the JDBC driver support for auto-generated keys.
Here’s a simple (silly) example that would generate a random ID (something you’d likely never do, but this demonstrates the flexibility and how MyBatis really doesn’t mind).
The selectKey statement would be run first, the Author id property would be set, and then the insert statement would be called. This gives you a similar behavior to an auto-generated key in your database without complicating your Java code.
1 2 3 4 5 6 7 8 9
<insertid="insertAuthor"> <selectKeykeyProperty="id"resultType="int"order="BEFORE"> select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1 </selectKey> insert into Author (id, username, password, email,bio, favourite_section) values (#{id}, #{username}, #{password}, #{email}, #{bio}, #{favouriteSection,jdbcType=VARCHAR}) </insert>
<!-- the transactional advice (what 'happens'; see the <aop:advisor/> bean below) --> <tx:adviceid="txAdvice"transaction-manager="txManager"> <!-- the transactional semantics... --> <tx:attributes> <!-- all methods starting with 'get' are read-only --> <tx:methodname="get*"read-only="true"/> <!-- other methods use the default transaction settings (see below) --> <tx:methodname="*"/> </tx:attributes> </tx:advice>
<!-- ensure that the above transactional advice runs for any execution of an operation defined by the FooService interface --> <aop:config> <aop:pointcutid="fooServiceOperation"expression="execution(* x.y.service.FooService.*(..))"/> <aop:advisoradvice-ref="txAdvice"pointcut-ref="fooServiceOperation"/> </aop:config>
......
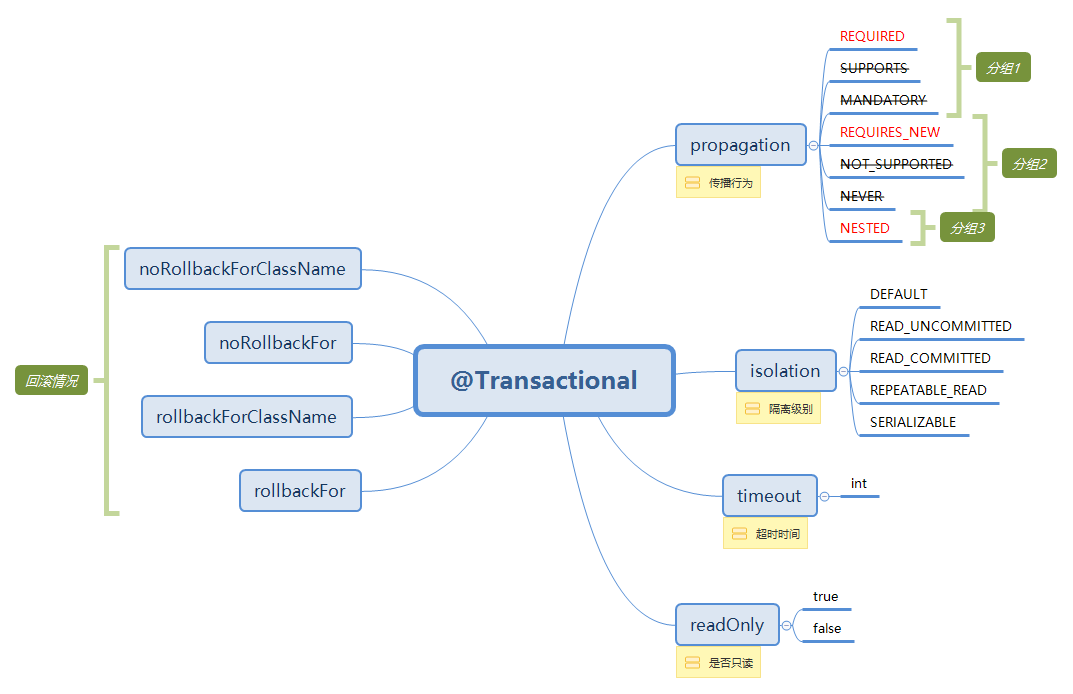
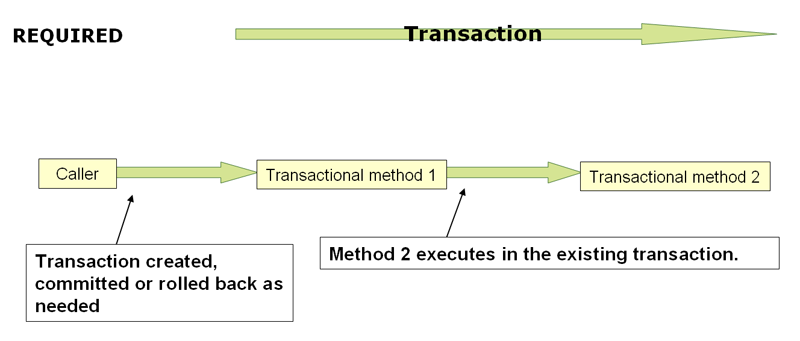
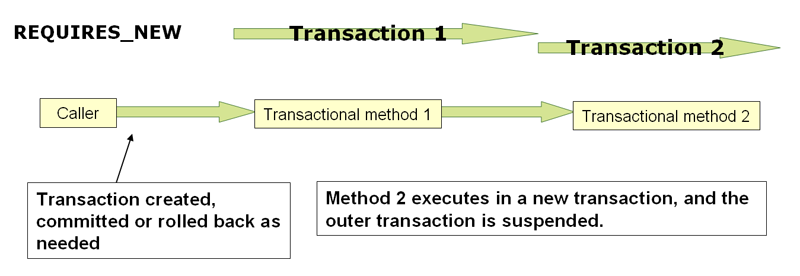
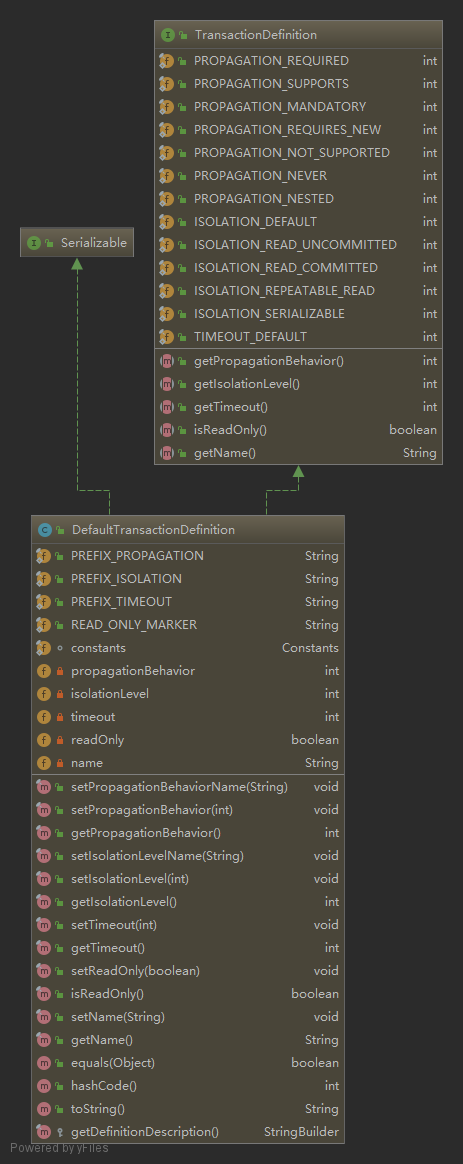
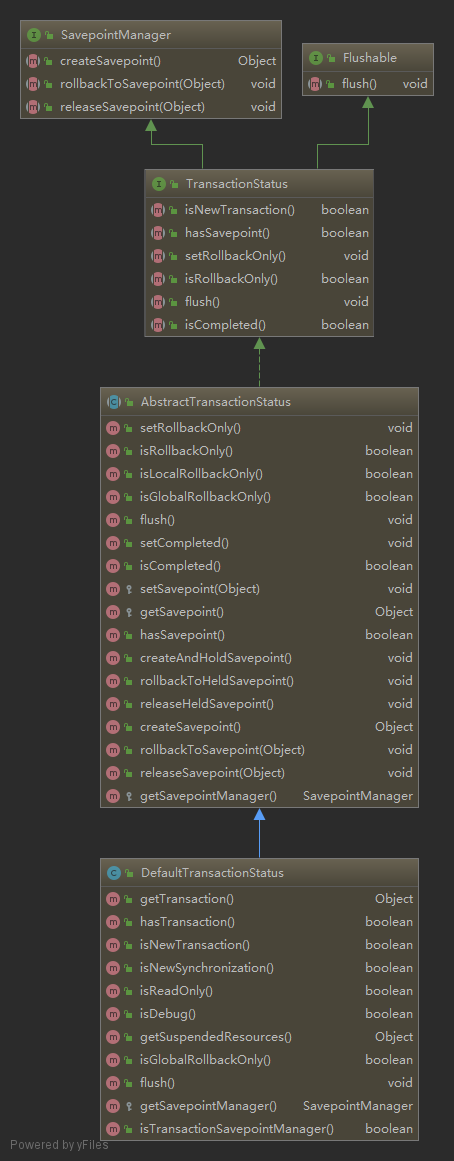
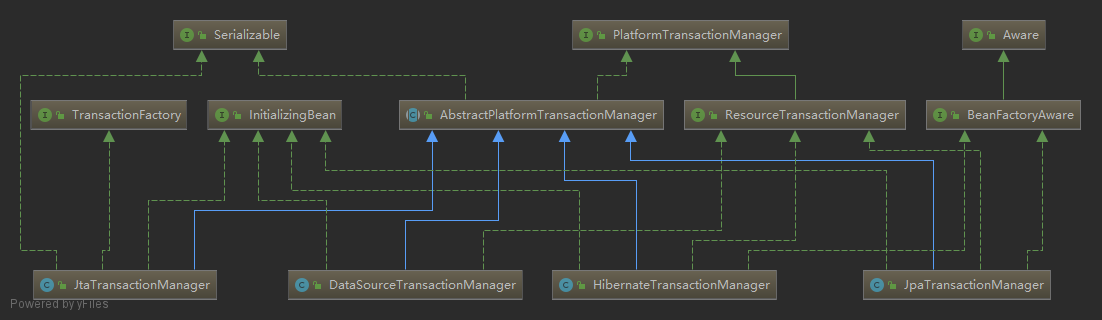
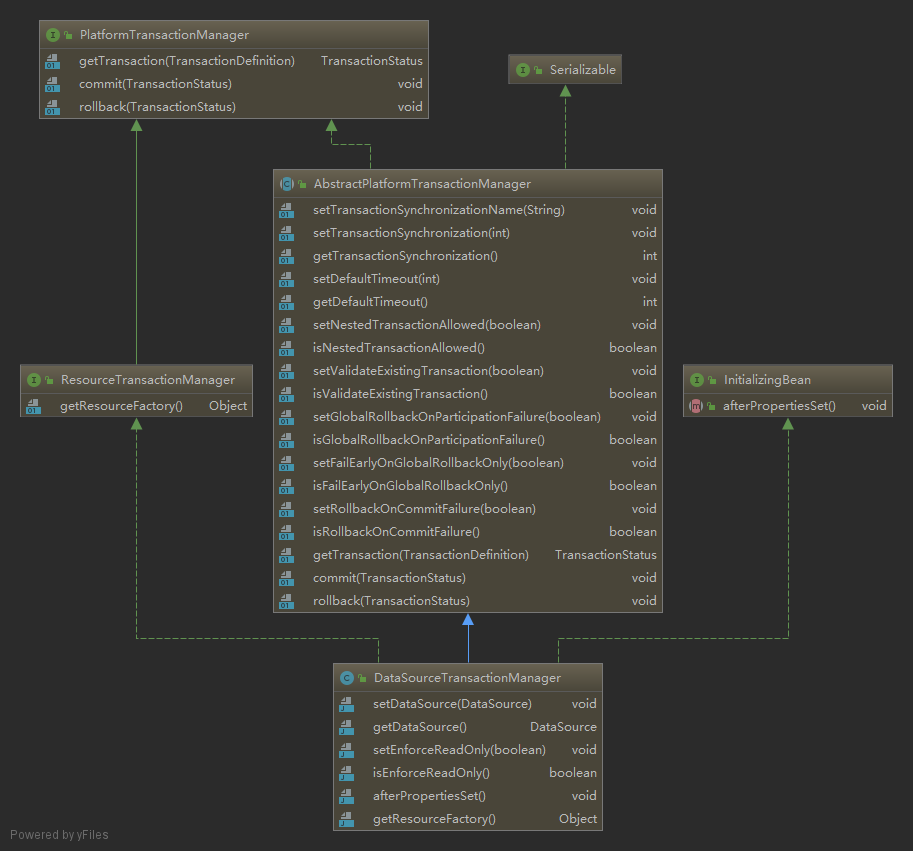
事务配置可通过修改 <tx:method/> 的属性,详见脑图。
基于注解方式配置事务管理
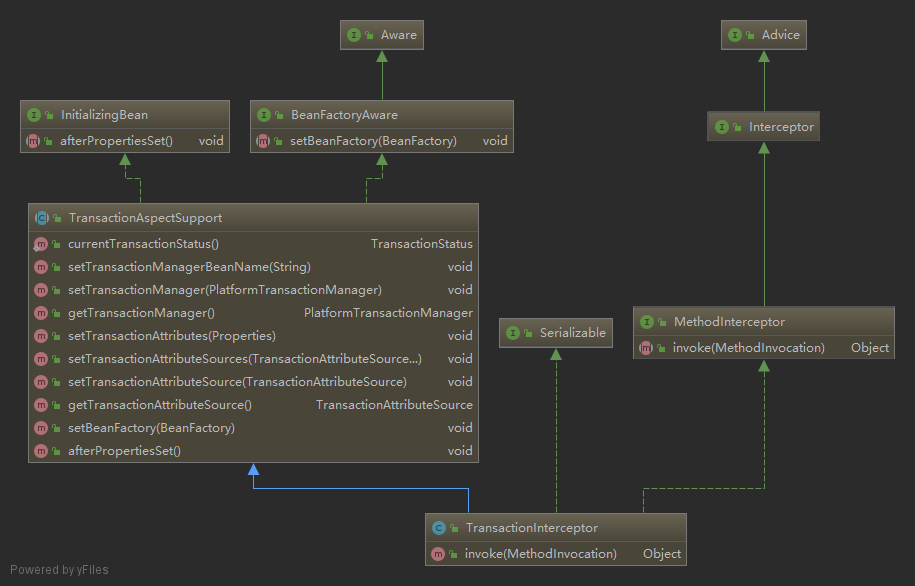
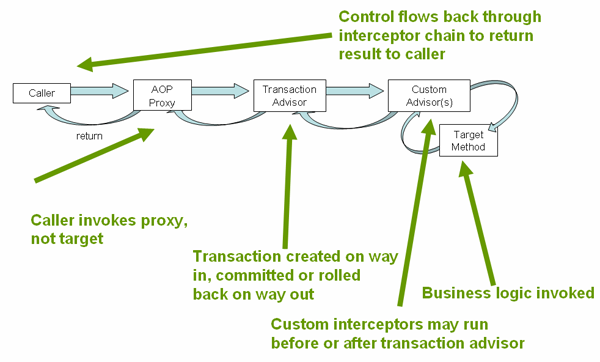
除了使用基于 XML 的方式(<tx:advice/>)声明事务配置之外,您还可以使用基于注解的方式(@Transactional )。直接在 Java 源代码中声明事务语义会使声明更靠近受影响的代码,易于配置和修改。这样之所以不存在过度耦合的原因是因为,无论如何,用于事务处理的代码几乎总是以事务的方式进行部署。
The default advice mode for processing @Transactional annotations is proxy, which allows for interception of calls through the proxy only. Local calls within the same class cannot get intercepted that way. For a more advanced mode of interception, consider switching to aspectj mode in combination with compile-time or load-time weaving.
In proxy mode (which is the default), only external method calls coming in through the proxy are intercepted. This means that self-invocation (in effect, a method within the target object calling another method of the target object) does not lead to an actual transaction at runtime even if the invoked method is marked with @Transactional.
The proxy-target-class attribute controls what type of transactional proxies are created for classes annotated with the @Transactional annotation. If proxy-target-class is set to true, class-based proxies are created. Ifproxy-target-class is false or if the attribute is omitted, standard JDK interface-based proxies are created. (See [aop-proxying] for a discussion of the different proxy types.)
The Spring team recommends that you annotate only concrete classes (and methods of concrete classes) with the @Transactional annotation, as opposed to annotating interfaces. You certainly can place the @Transactional annotation on an interface (or an interface method), but this works only as you would expect it to if you use interface-based proxies. The fact that Java annotations are not inherited from interfaces means that, if you use class-based proxies (proxy-target-class="true") or the weaving-based aspect (mode="aspectj"), the transaction settings are not recognized by the proxying and weaving infrastructure, and the object is not wrapped in a transactional proxy.
When you use proxies, you should apply the @Transactional annotation only to methods with public visibility. If you do annotate protected, private or package-visible methods with the @Transactional annotation, no error is raised, but the annotated method does not exhibit the configured transactional settings. If you need to annotate non-public methods, consider using AspectJ.
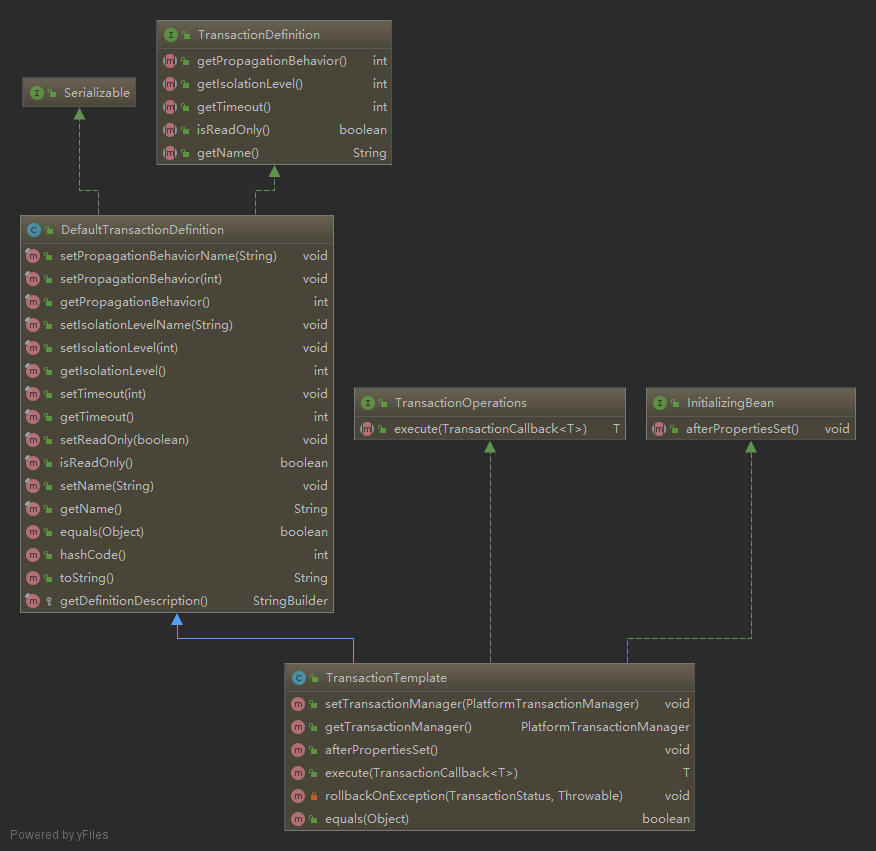
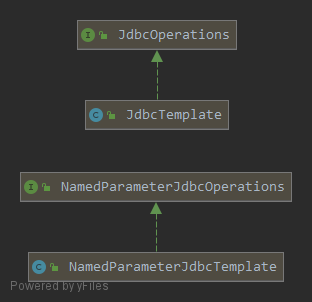
Spring 的 JDBC 框架承担了资源管理和异常处理的工作,从而简化了底层 JDBC API 代码,让我们只需编写从数据库读写数据所需的代码。具体特性如下:
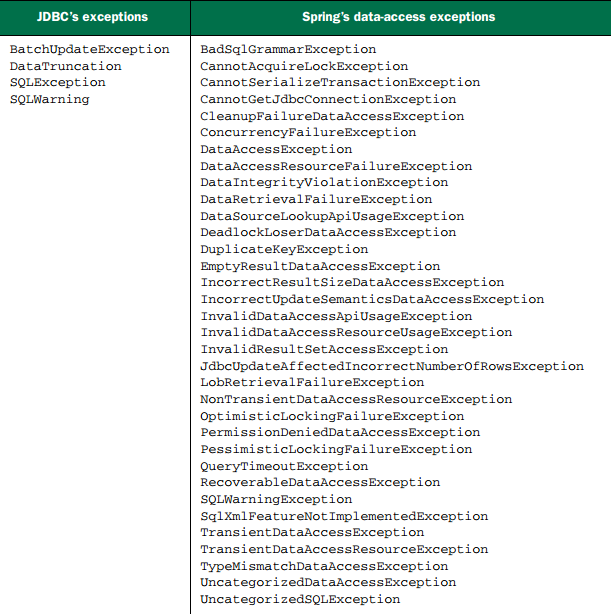
Spring 为读取和写入数据库的几乎所有错误提供了丰富的异常,且不与特定的持久化框架相关联(如下图)。异常都继承自的父类 DataAccessException,是一个非受检异常,无需捕获,因为 Spring 认为触发异常的很多问题是不能在 catch 代码块中修复,因此不强制开发人员编写 catch 代码块。这把是否要捕获异常的权利留给了开发人员。
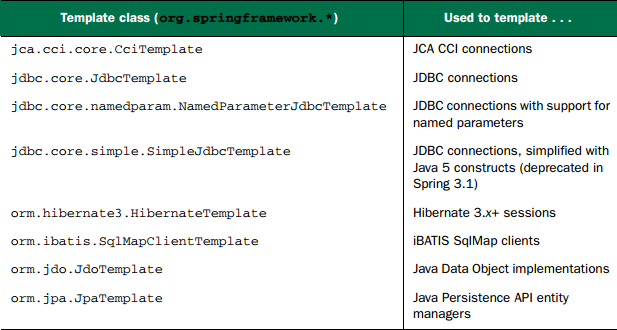
Spring 将数据访问过程中固定的和可变的部分明确划分为两个不同的类:模板(template) 和 回调(callback)。模板管理过程中固定的部分(如事务控制、资源管理、异常处理),而回调处理自定义的数据访问代码(如 SQL 语句、绑定参数、整理结果集)。针对不同的持久化平台,Spring 提供了多个可选的模板:
依赖安装
要在 Spring 中使用 JDBC,需要依赖 spring-jdbc。如果使用 Spring Boot 的话,可以直接导入起步依赖 spring-boot-starter-jdbc:
1 2 3 4 5 6 7 8 9 10 11
<!-- Spring JDBC 起步依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency>
<!-- MySQL JDBC 驱动程序 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency>
List<TestPO> testPOList = jdbcOperations.query( "SELECT id, name, city FROM test WHERE name = ? AND city = ?", (rs, rowNum) -> newTestPO( rs.getLong("id"), rs.getString("name"), rs.getString("city") ), "李四", "beijing" ); log.info("Result is {}", testPOList); // Result is [TestPO(id=2, name=李四, city=beijing)]
TestPOtestPO= jdbcOperations.queryForObject( "SELECT id, name, city FROM test WHERE id = ?", (rs, rowNum) -> newTestPO( rs.getLong("id"), rs.getString("name"), rs.getString("city") ), 2 ); log.info("Result is {}", testPO); // Result is TestPO(id=2, name=李四, city=beijing)
Stringname= jdbcOperations.queryForObject("SELECT name FROM test WHERE id = ?", String.class, 2); log.info("Result is {}", name); // Result is 李四
List<String> names = jdbcOperations.queryForList("SELECT name FROM test WHERE city = ?", String.class, "beijing"); log.info("Result is {}", names); // Result is [李四, 王五]
List<Map<String, Object>> testMapList = jdbcOperations.queryForList("SELECT id, name, city FROM test WHERE city = ?", "beijing"); log.info("Result is {}", testMapList); // Result is [{id=2, name=李四, city=beijing}, {id=3, name=王五, city=beijing}]
Map<String, Object> testMap = jdbcOperations.queryForMap("SELECT id, name, city FROM test WHERE id = ?", 2); log.info("Result is {}", testMap); // Result is {id=2, name=李四, city=beijing}
List<TestPO> testPOList = namedParameterJdbcOperations.query( "SELECT id, name, city FROM test WHERE name = :name AND city = :city", paramMap, (rs, rowNum) -> newTestPO( rs.getLong("id"), rs.getString("name"), rs.getString("city") ) );
log.info("Result is {}", testPOList); // Result is [TestPO(id=2, name=李四, city=beijing)]
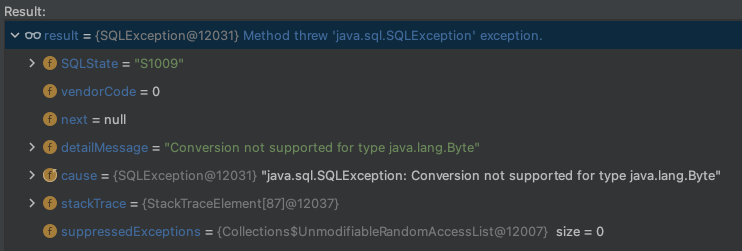
// ... will convert from the SQL type of the column to the requested Java data type, if the conversion is supported. If the conversion is not supported or null is specified for the type, a `SQLException` is thrown. <T> T getObject(int columnIndex, Class<T> type)throws SQLException; <T> T getObject(String columnLabel, Class<T> type)throws SQLException;
⚠️ 特别注意:对于最后一组动态数据访问方法,参数二 type 的值要与 ResultSetMetaData.GetColumnClassName() 返回的类型相匹配,类型转换才能成功。否则抛出异常如下:
Some databases need to know the value’s type even if the value itself is NULL. For this reason, for maximum portability, it’s the JDBC specification itself that requires the java.sql.Types to be specified:
PreparedStatement 接口:
1 2 3
// Sets the designated parameter to SQL NULL. voidsetNull(int parameterIndex, int sqlType)throws SQLException; voidsetNull(int parameterIndex, int sqlType, String typeName)throws SQLException;
PreparedStatement prepareStatement(String sql, int autoGeneratedKeys)throws SQLException;
autoGeneratedKeys - a flag indicating whether auto-generated keys should be returned; one of Statement.RETURN_GENERATED_KEYS or Statement.NO_GENERATED_KEYS
1 2 3 4 5 6 7 8 9 10 11 12 13
/** * The constant indicating that generated keys should be made available for retrieval. * * @since 1.4 */ intRETURN_GENERATED_KEYS=1;
/** * The constant indicating that generated keys should not be made available for retrieval. * * @since 1.4 */ intNO_GENERATED_KEYS=2;
// 调用 getGeneratedKeys ,然后又会获取到一个 ResultSet 对象,从这个游标中就可以获取到刚刚插入数据的 id ResultSetrs= ps.getGeneratedKeys(); intid=0; if (rs.next()) { id = rs.getInt(1); } return id;
批处理
PreparedStatement 还提供了批处理方式,减少网络请求,提升性能,API 如下:
1 2 3 4 5 6 7 8 9 10
/** * Adds a set of parameters to this <code>PreparedStatement</code> * object's batch of commands. * * @exception SQLException if a database access error occurs or * this method is called on a closed <code>PreparedStatement</code> * @see Statement#addBatch * @since 1.2 */ voidaddBatch()throws SQLException;
未使用批处理方法:
1 2 3 4 5 6 7 8 9
PreparedStatementps= conn.prepareStatement("INSERT into employees values (?, ?, ?)");
for (n = 0; n < 100; n++) { ps.setString(name[n]); ps.setLong(id[n]); ps.setInt(salary[n]); // 多次执行PreparedStatement,多次数据库请求(网络请求) ps.executeUpdate(); }
使用批处理方法,一次性执行多条 SQL:
1 2 3 4 5 6 7 8 9 10 11
PreparedStatementps= conn.prepareStatement("INSERT into employees values (?, ?, ?)"); for (n = 0; n < 100; n++) { ps.setString(name[n]); ps.setLong(id[n]); ps.setInt(salary[n]); // 添加批次 ps.addBatch(); } // 调用父接口 Statement#executeBatch() 执行批次 ps.executeBatch();
JDBC 4.1 (Java SE 7) introduces the ability to use a try-with-resources statement to automatically close java.sql.Connection, java.sql.Statement, and java.sql.ResultSet objects, regardless of whether a SQLException or any other exception has been thrown. See The try-with-resources Statement for more information.
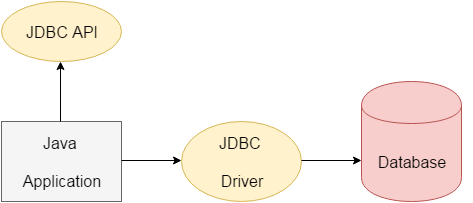
在 JDBC 之前,ODBC API 是用于连接和执行命令的数据库 API 标准。但是,ODBC API 是使用 C 语言编写的驱动程序,依赖于平台。这就是为什么 Java 定义了自己的 JDBC API,它使用的 JDBC 驱动程序,是用 Java 语言编写的,具有与平台无关的特性,支持跨平台部署,性能也较好。
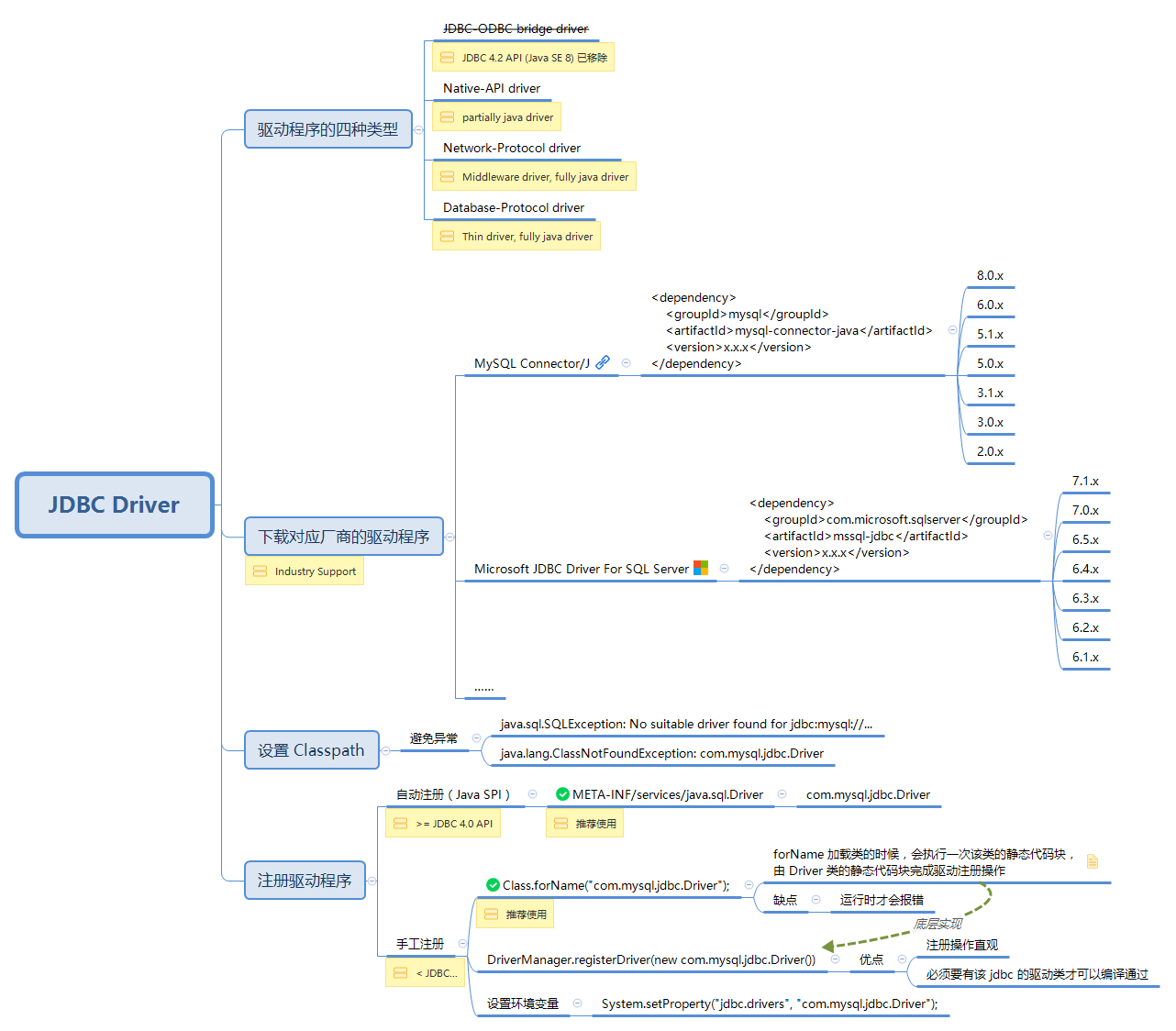
什么是 JDBC 驱动程序?
由于 JDBC API 只是一套接口规范,因此要使用 JDBC API 操作数据库,首先需要选择合适的驱动程序:
驱动程序四种类型
有四种类型的 JDBC 驱动程序:
JDBC-ODBC bridge driver (In Java 8, the JDBC-ODBC Bridge has been removed.)
因为ODBC 不适合直接在 Java 中使用,因为它使用 C 语言接口。从Java 调用本地 C代码在安全性、实现、坚固性和程序的自动移植性方面都有许多缺点。从 ODBC C API 到 Java API 的字面翻译是不可取的。例如,Java 没有指针,而 ODBC 却对指针用得很广泛(包括很容易出错的指针”void *”)。
javax.net.ssl.SSLException MESSAGE: closing inbound before receiving peer's close_notify
STACKTRACE:
javax.net.ssl.SSLException: closing inbound before receiving peer's close_notify at sun.security.ssl.Alert.createSSLException(Alert.java:133) at sun.security.ssl.Alert.createSSLException(Alert.java:117) at sun.security.ssl.TransportContext.fatal(TransportContext.java:340) at sun.security.ssl.TransportContext.fatal(TransportContext.java:296) at sun.security.ssl.TransportContext.fatal(TransportContext.java:287) at sun.security.ssl.SSLSocketImpl.shutdownInput(SSLSocketImpl.java:737) at sun.security.ssl.SSLSocketImpl.shutdownInput(SSLSocketImpl.java:716) at com.mysql.cj.protocol.a.NativeProtocol.quit(NativeProtocol.java:1319) at com.mysql.cj.NativeSession.quit(NativeSession.java:182) at com.mysql.cj.jdbc.ConnectionImpl.realClose(ConnectionImpl.java:1750) at com.mysql.cj.jdbc.ConnectionImpl.close(ConnectionImpl.java:720) at com.zaxxer.hikari.pool.PoolBase.quietlyCloseConnection(PoolBase.java:135) at com.zaxxer.hikari.pool.HikariPool.lambda$closeConnection$1(HikariPool.java:441) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
Use server-side prepared statements if the server supports them?
MySQL 是否默认开启预编译,与 MySQL Server 的版本无关,而与 MySQL Connector/J(驱动程序)的版本有关,Connector/J 5.0.5 之前的版本默认开启预编译。Connector/J 5.0.5 及以后的版本默认不开启预编译,想启用 MySQL 预编译,就必须设置 useServerPrepStmts=true。
Allow the use of ; to delimit multiple queries during one statement (true/false). Default is false, and it does not affect the addBatch() and executeBatch() methods, which rely on rewriteBatchedStatements instead.
Should the driver use multi-queries (regardless of the setting of allowMultiQueries) as well as rewriting of prepared statements for INSERT into multi-value inserts when executeBatch() is called?
Notice that this has the potential for SQL injection if using plain java.sql.Statement and your code doesn’t sanitize input correctly.
Notice that for prepared statements, server-side prepared statements can not currently take advantage of this rewrite option, and that if you don’t specify stream lengths when using PreparedStatement.set*Stream(), the driver won’t be able to determine the optimum number of parameters per batch and you might receive an error from the driver that the resultant packet is too large.
Statement.getGeneratedKeys() for these rewritten statements only works when the entire batch includes INSERT statements.
Please be aware using rewriteBatchedStatements=true with INSERT .. ON DUPLICATE KEY UPDATE that for rewritten statement server returns only one value as sum of all affected (or found) rows in batch and it isn’t possible to map it correctly to initial statements; in this case driver returns 0 as a result of each batch statement if total count was 0, and the Statement.SUCCESS_NO_INFO as a result of each batch statement if total count was > 0.
在 MySQL 中,rewriteBatchedStatements 的默认值取决于 MySQL 版本和 JDBC 驱动程序的配置。
在 MySQL 8.0 版本之前,rewriteBatchedStatements 的默认值是 false,这意味着批处理语句不会被重写优化。
从 MySQL 8.0 版本开始,rewriteBatchedStatements 的默认值被更改为 true,以提高默认情况下的性能。
Maximum allowed packet size to send to server. If not set, the value of system variable max_allowed_packet will be used to initialize this upon connecting. This value will not take effect if set larger than the value of max_allowed_packet. Also, due to an internal dependency with the property “blobSendChunkSize“, this setting has a minimum value of “8203” if “useServerPrepStmts“ is set to “true“.
publicclassDriverManager { /** * Load the initial JDBC drivers by checking the System property * jdbc.properties and then use the {@code ServiceLoader} mechanism */ static { loadInitialDrivers(); println("JDBC DriverManager initialized"); }
privatestaticvoidloadInitialDrivers() { String drivers; try { drivers = AccessController.doPrivileged(newPrivilegedAction<String>() { public String run() { return System.getProperty("jdbc.drivers"); } }); } catch (Exception ex) { drivers = null; } // If the driver is packaged as a Service Provider, load it. // Get all the drivers through the classloader // exposed as a java.sql.Driver.class service. // ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(newPrivilegedAction<Void>() { public Void run() {
/* Load these drivers, so that they can be instantiated. * It may be the case that the driver class may not be there * i.e. there may be a packaged driver with the service class * as implementation of java.sql.Driver but the actual class * may be missing. In that case a java.util.ServiceConfigurationError * will be thrown at runtime by the VM trying to locate * and load the service. * * Adding a try catch block to catch those runtime errors * if driver not available in classpath but it's * packaged as service and that service is there in classpath. */ try{ while(driversIterator.hasNext()) { driversIterator.next(); } } catch(Throwable t) { // Do nothing } returnnull; } });
@Override public java.sql.Connection connect(String url, Properties info)throws SQLException {
try { if (!ConnectionUrl.acceptsUrl(url)) { /* * According to JDBC spec: * The driver should return "null" if it realizes it is the wrong kind of driver to connect to the given URL. This will be common, as when the * JDBC driver manager is asked to connect to a given URL it passes the URL to each loaded driver in turn. */ returnnull; }
ConnectionUrlconStr= ConnectionUrl.getConnectionUrlInstance(url, info); switch (conStr.getType()) { case SINGLE_CONNECTION: return com.mysql.cj.jdbc.ConnectionImpl.getInstance(conStr.getMainHost());
case LOADBALANCE_CONNECTION: return LoadBalancedConnectionProxy.createProxyInstance((LoadbalanceConnectionUrl) conStr);
case FAILOVER_CONNECTION: return FailoverConnectionProxy.createProxyInstance(conStr);
case REPLICATION_CONNECTION: return ReplicationConnectionProxy.createProxyInstance((ReplicationConnectionUrl) conStr);
default: returnnull; }
} catch (UnsupportedConnectionStringException e) { // when Connector/J can't handle this connection string the Driver must return null returnnull;
/** * The database URL type which is determined by the scheme section of the connection string. */ publicenumType { SINGLE_CONNECTION("jdbc:mysql:", HostsCardinality.SINGLE), // FAILOVER_CONNECTION("jdbc:mysql:", HostsCardinality.MULTIPLE), // LOADBALANCE_CONNECTION("jdbc:mysql:loadbalance:", HostsCardinality.ONE_OR_MORE), // REPLICATION_CONNECTION("jdbc:mysql:replication:", HostsCardinality.ONE_OR_MORE), // XDEVAPI_SESSION("mysqlx:", HostsCardinality.ONE_OR_MORE);