响应式编程系列(四)Reactor 如何包装同步阻塞调用?
问题背景
<Spring Webflux: EventLoop vs Thread per Request Model>
EventLoop is a Non-Blocking I/O Thread (NIO) which runs continuously and takes new requests from a range of socket channels.
What happens if an application block the EventLoop for a long time due to any of the following reasons?
- High CPU intensive work
- Database operations like read/write etc.
- File read/write
- Any call to another application over the network.
In these cases, EventLoop will get blocked and we could be in the same situation where our application could become slow or unresponsive very soon.
EventLoop should delegate the request to another worker thread (Worker Thread perform these long tasks) and return the result asynchronously via a callback to unblock the EventLoop for new request handling.
These Worker threads can be created by the developer or can choose the ‘Scheduler’ strategy from reactive libraries like Reactor, RxJava or other. Remember to use these threads on an ad-hoc basis to keep the resource utilization minimum.
This approach helps when an application has multiple APIs and some of them are slow due to network calls or high CPU intensive work. Here, applications can still be partially available and responsive to user requests.
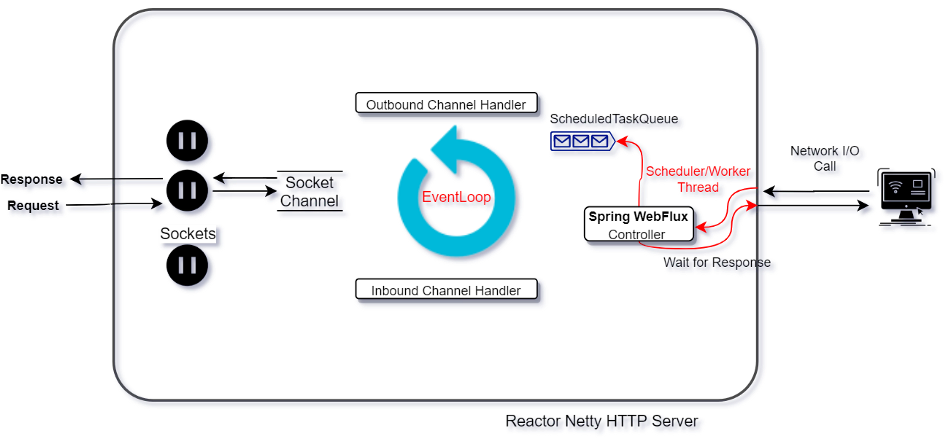
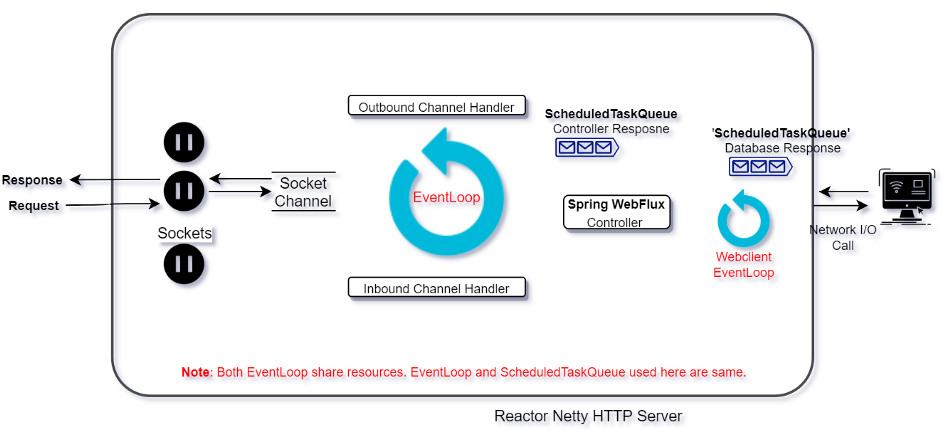
Ideally, to make your application fully reactive, there shouldn’t be any single thread which can block. Thus far, we are able to unblock our request handling thread i.e. EventLoop. But our Worker Threads are still handling blocking tasks and we can’t increase these thread count indefinitely when more such requests come, as that could also lead us to a new problem of managing large threads which can severely affect CPU utilization and memory usage. In such a case, we would need to use Worker Threads efficiently and strategically.
For most of the blocking cases mentioned above, it’s better to use a fully reactive approach. We have to choose DBs which provide reactive drivers for DB calls. Also, we have reactive Http Client to make call to another application over network e.g. Spring Webflux Reactive WebClient, which basically use Reactor Netty library i.e. EventLoop model. So, if our application uses Netty and Reactive Webclient, then EventLoop resources will be shared.
Advantage:
- Lightweight request processing thread
- Optimum utilization of hardware resources
- Single EventLoop can be shared between http client and request processing.
- Single thread can handle requests over many sockets i.e. from different clients.
- This model provides support for backpressure handling in case of infinite stream response.
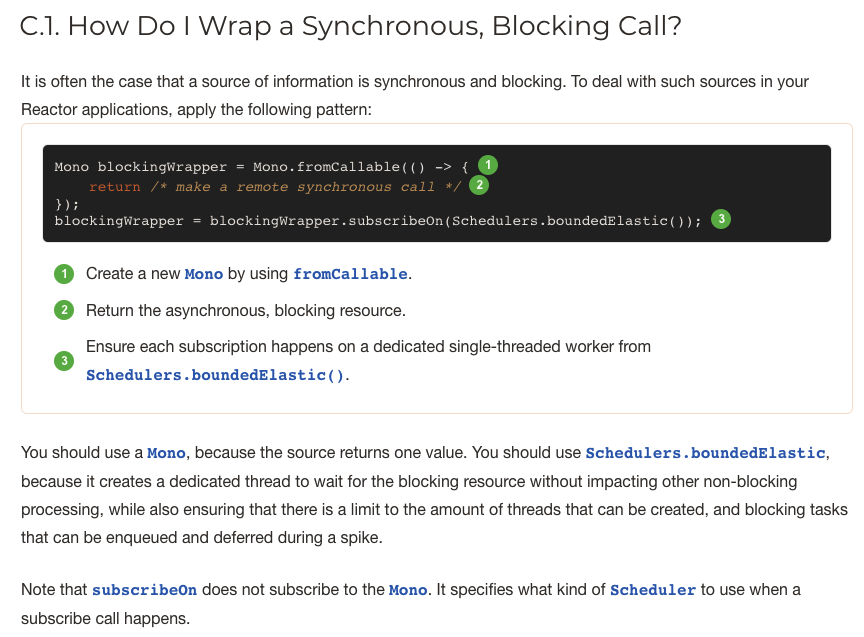
如何包装同步阻塞调用?
什么是 Scheduler?
In Netty, worker threads are often named scheduler (or similar) because of the way they manage and schedule tasks in the network I/O processing loop, specifically the event loop.
如何创建 Scheduler?
通过工厂类 Schedulers 创建 Scheduler:
https://projectreactor.io/docs/core/release/api/reactor/core/scheduler/Schedulers.html
| Return a shared instance | Return a new instance | Description | Notes |
|---|---|---|---|
immediate() |
/ | No execution context | at processing time, the submitted Runnable will be directly executed, effectively running them on the current Thread (can be seen as a “null object” or no-op Scheduler). |
single() |
newSingle(...) |
A single, reusable thread. | Note that this method reuses the same thread for all callers, until the Scheduler is disposed. |
elastic() |
newElastic(...) |
An unbounded elastic thread pool. | This one is no longer preferred with the introduction of Schedulers.boundedElastic(), as it has a tendency to hide backpressure problems and lead to too many threads (see below). |
boundedElastic() |
newBoundedElastic(...) |
A bounded elastic thread pool. | Like its predecessor elastic(), it creates new worker pools as needed and reuses idle ones. Worker pools that stay idle for too long (the default is 60s) are also disposed.Unlike its predecessor elastic(), it has a cap on the number of backing threads it can create (default is number of CPU cores x 10). Up to 100 000 tasks submitted after the cap has been reached are enqueued and will be re-scheduled when a thread becomes available.This is a better choice for I/O blocking work. While it is made to help with legacy blocking code if it cannot be avoided. Schedulers.boundedElastic() is a handy way to give a blocking process its own thread so that it does not tie up other resources. See How Do I Wrap a Synchronous, Blocking Call?, but doesn’t pressure the system too much with new threads. |
parallel() |
newParallel(...) |
A fixed pool of workers that is tuned for parallel work. | It creates as many workers as you have CPU cores. |
fromExecutorService(ExecutorService) |
A Customize thread pool. | Create a Scheduler out of any pre-existing ExecutorService |
delayElements
Signals are delayed and continue on the parallel default Scheduler
Signals are delayed and continue on an user-specified Scheduler
如何使用 Scheduler?
Reactor offers two means of switching the execution context (or
Scheduler) in a reactive chain:publishOnandsubscribeOn. Both take aSchedulerand let you switch the execution context to that scheduler. But the placement ofpublishOnin the chain matters, while the placement ofsubscribeOndoes not. To understand that difference, you first have to remember that nothing happens until you subscribe.Let’s have a closer look at the
publishOnandsubscribeOnoperators:
例子一
演示流是运行在 subscribe() 方法调用的线程上,且大多数操作符继续在前一个操作符执行的线程中工作。
most operators continue working in the
Threadon which the previous operator executed. Unless specified, the topmost operator (the source) itself runs on theThreadin which thesubscribe()call was made. The following example runs aMonoin a new thread:
1 | // The Mono<String> is assembled in thread main. |
输出结果:
1 | 21:02:18.436 [Thread-0] INFO FluxTest - fromSupplier |
例子二
演示如何使用 subscribeOn 方法,简化上述例子一。
1 | CountDownLatch countDownLatch = new CountDownLatch(1); |
输出结果:
1 | 21:31:52.563 [subscribeOn-1] INFO FluxTest - fromSupplier |
例子三
演示 publishOn 如何影响其后续操作符的执行线程。
publishOntakes signals from upstream and replays them downstream while executing the callback on a worker from the associatedScheduler. Consequently, it affects where the subsequent operators execute (until anotherpublishOnis chained in), as follows:
1 | CountDownLatch countDownLatch = new CountDownLatch(1); |
输出结果:
1 | 21:32:36.975 [subscribeOn-1] INFO FluxTest - fromSupplier |
参考
Reactor Core Features - Threading and Schedulers
Appendix C.1. How Do I Wrap a Synchronous, Blocking Call?
Appendix C.6. How Do I Ensure Thread Affinity when I Use publishOn()?
https://www.woolha.com/tutorials/project-reactor-publishon-vs-subscribeon-difference
In contrast to the blocking nature of JDBC, R2DBC allows you to work with SQL databases using a reactive API.