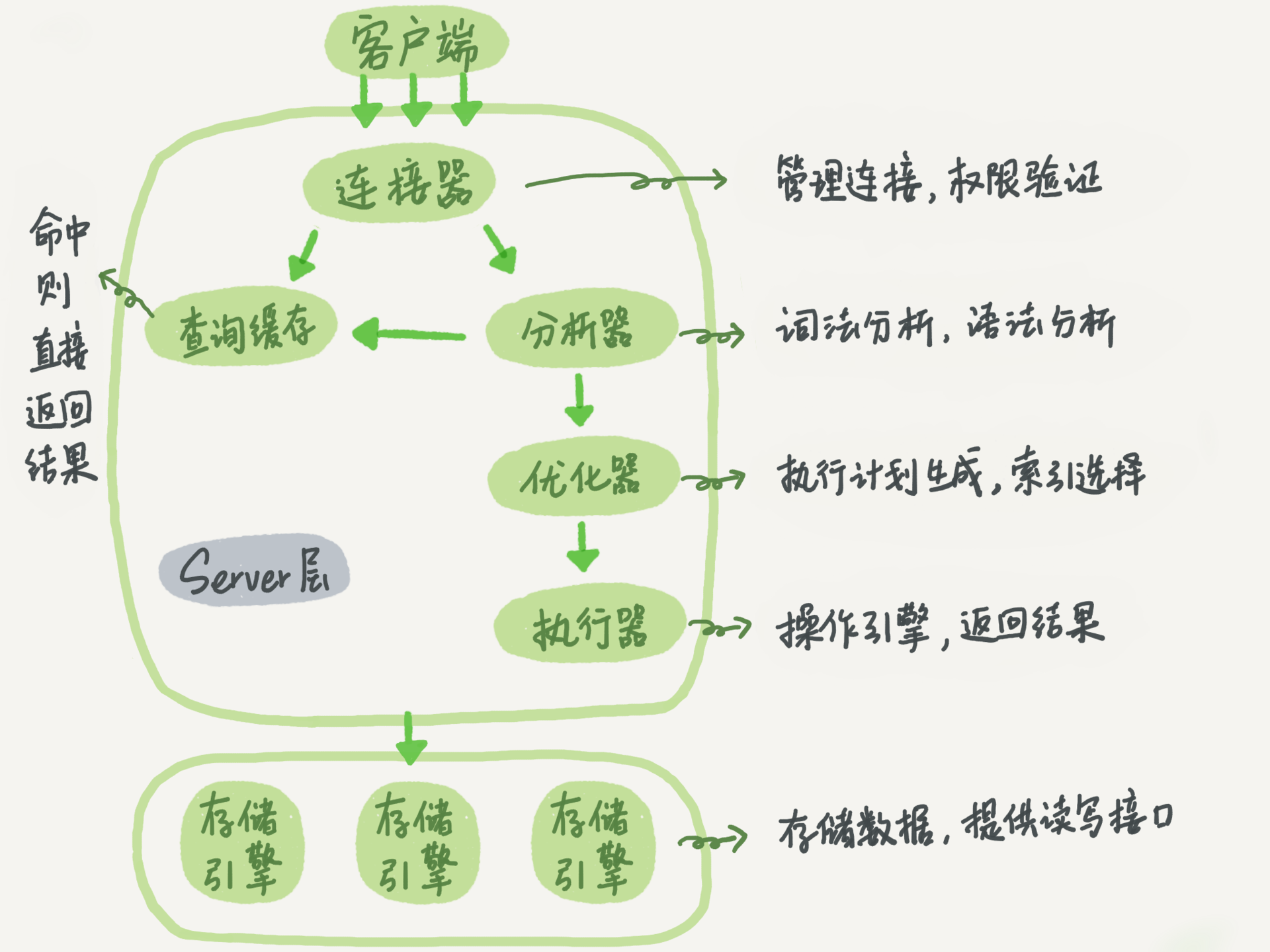
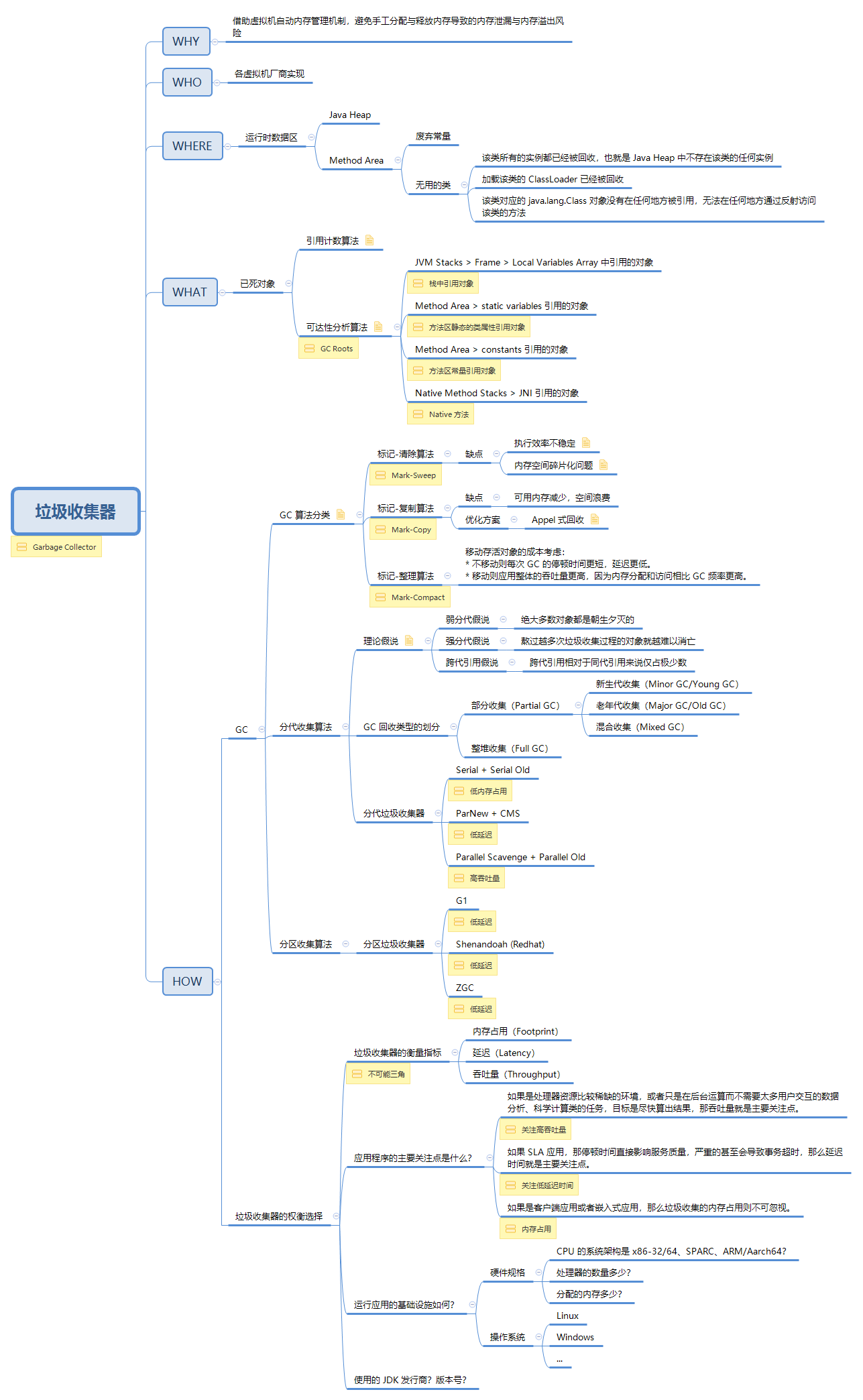
索引是存储引擎用于快速找到记录的一种数据结构。在 MySQL 中,索引是在存储引擎层而不是服务器层实现的(如下图)。所以,并没有统一的索引标准:不同存储引擎的索引的工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。
常见索引类型
MySQL 支持的常见索引类型:
B+Tree 索引
Hash index(哈希索引)
R-Tree index(空间数据索引)
Full-text index(全文索引)
……
本文只探讨最常用的 B-Tree 索引。
B+Tree 数据结构
B+Tree 索引特性
当我们谈论索引的时候,如果没有特别指明类型,那多半说的是 B+Tree 索引。InnoDB 存储引擎默认使用的也是 B+Tree 数据结构来存储数据。 索引可以包含一个或多个列的值。如果包含多个列(称为“联合索引”),那么列的顺序至关重要,因为 MySQL 只能高效地使用索引的 最左前缀列。创建一个包含两个列的索引,和创建两个只包含一列的索引是大不相同的,下面看个例子:
1 2 3 4 5 6 7
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
可以使用该 B-Tree 索引的查询类型:
全值匹配
全值匹配(Match the full value):
1 2 3
SELECT * FROM people WHERE last_name = 'Wu' AND first_name = 'Qida' AND dob = '2018-01-01';
匹配最左前缀
匹配最左前缀(Match a leftmost prefix):
1 2 3 4 5 6 7
SELECT * FROM people WHERE last_name = 'Wu';
SELECT * FROM people WHERE last_name = 'Wu' AND first_name = 'Qida';
匹配列前缀
匹配列前缀(Match a column prefix):
1 2 3
SELECT * FROM people WHERE last_name LIKE 'W%';
注意 MySQL LIKE 的限制:
MySQL can’t perform the LIKE operation in the index. This is a limitation of the low-level storage engine API, which in MySQL 5.5 and earlier allows only simple comparisons (such as equality, inequality, and greater-than) in index operations.
MySQL can perform prefix-match LIKE patterns in the index because it can convert them to simple comparisons, but the leading wildcard in the query makes it impossible for the storage engine to evaluate the match. Thus, the MySQL server itself will have to fetch and match on the row’s values, not the index’s values.
匹配范围值
匹配范围值(Match a range of values):
1 2 3
SELECT * FROM people WHERE last_name BETWEEN 'Wu' AND 'Li';
精确匹配某一列,并范围匹配另外一列
精确匹配某一列,并范围匹配另外一列(Match one part exactly and match a range on another part):
1 2 3
SELECT * FROM people WHERE last_name = 'Wu' And first_name LIKE 'Q%';
覆盖索引
只访问索引列的查询(Index-only queries):
1 2 3
SELECT last_name, first_name, dob FROM people WHERE last_name = 'Wu' AND first_name = 'Qida' AND dob = '2018-01-01';
-- 错误示范 SELECT* FROM t_order WHERE merchant_no =2016;
-- 正确示范 SELECT* FROM t_order WHERE merchant_no ='2016';
字符串索引优化
常规方式
直接创建完整索引
优点:可以使用覆盖索引
缺点:比较占用空间
创建前缀索引
优点:节省空间
缺点:
需要计算好区分度,以定义合适的索引长度,否则会增加回表次数
无法使用覆盖索引
区分度计算方法:
1 2 3 4 5 6
select count(distinctleft(email,4)) /count(distinct email) as L4, count(distinctleft(email,5)) /count(distinct email) as L5, count(distinctleft(email,6)) /count(distinct email) as L6, count(distinctleft(email,7)) /count(distinct email) as L7, from t1;
SELECT*FROM tbl_name WHERE primary_key_part1 =1AND primary_key_part2 =2;
SELECT*FROM tbl_name WHERE unique_key ='001';
SELECT*FROM tbl_name WHERE unique_key_part1 ='001'AND unique_key_part2 ='002';
SELECT*FROM ref_table,other_table WHERE ref_table.unique_key_column = other_table.unique_key_column AND other_table.unique_key_column ='001';
eq_ref
对于 other_table 中的每行,仅从 ref_table 中读取唯一一行。eq_ref 类型用于主键索引(PRIMARY KEY )或 NOT NULL 的唯一索引(UNIQUE KEY),且索引被表连接所使用时。除了 system 和 const 类型之外,这是最好的连接类型。select_type=SIMPLE 简单查询类型不会出现这种类型。
例子:
1 2 3 4 5 6
SELECT*FROM ref_table,other_table WHERE ref_table.unique_key_column = other_table.column; SELECT*FROM ref_table,other_table WHERE ref_table.unique_key_column_part1 = other_table.column AND ref_table.unique_key_column_part2 =1;
ref
对于 other_table 中的每行,从 ref_table 中读取所有匹配行。ref 类型用于普通索引或联合索引的最左前缀列(leftmost prefix of the key),即无法根据键值查询到唯一一行。如果使用的索引仅匹配几行结果,则也是一种很好的连接类型。
例子:
1 2 3 4 5 6 7 8 9 10
SELECT*FROM ref_table WHERE key_column = expr;
SELECT*FROM ref_table WHERE key_column_part1 = expr;
SELECT*FROM ref_table,other_table WHERE ref_table.key_column = other_table.column; SELECT*FROM ref_table,other_table WHERE ref_table.key_column_part1 = other_table.column AND ref_table.key_column_part2 =1;
Prefixes, defined by the length attribute, can be up to 767 bytes long for InnoDB tables or 3072 bytes if the innodb_large_prefix option is enabled. For MyISAM tables, the prefix length limit is 1000 bytes.
-- key_len: 1 * 3 + 2 + 1 = 6 Bytes mysql> explain select password from student where password ='pete'; +----+-------------+---------+------+---------------+--------------+---------+-------+------+--------------------------+ | id | select_type |table| type | possible_keys | key | key_len |ref|rows| Extra | +----+-------------+---------+------+---------------+--------------+---------+-------+------+--------------------------+ |1| SIMPLE | student |ref| idx_password | idx_password |6| const |1|Usingwhere; Using index | +----+-------------+---------+------+---------------+--------------+---------+-------+------+--------------------------+
如果使用过长的索引,例如修改了字符串编码类型、增加联合索引列,则报错如下:
1
[Err] 1071 - Specified key was too long; max key length is 767 bytes
ref
ref 显示与 key 列(实际选择的索引)比较的内容,可选值:
列名
const:常量值
func:值为某些函数的结果
NULL:范围查询(type=range)
例如联合索引如下,使用三个索引列查询时,执行计划如下(注意 key_len 和 ref):
1 2 3 4 5 6 7 8 9 10
`channel_task_no` varchar(60) NOT NULL, `reconciliation_code` tinyint(4) unsigned NOT NULLDEFAULT'0', `reconciliation_status` tinyint(4) unsigned NOT NULLDEFAULT'0', KEY `idx_taskno_rcode_rstatus` (`channel_task_no`,`reconciliation_code`,`reconciliation_status`) USING BTREE
+----+-------------+-------+------+--------------------------+--------------------------+---------+-------------------+------+-----------------------+ | id | select_type |table| type | possible_keys | key | key_len |ref|rows| Extra | +----+-------------+-------+------+--------------------------+--------------------------+---------+-------------------+------+-----------------------+ |1| SIMPLE | t_xxx |ref| idx_taskno_rcode_rstatus | idx_taskno_rcode_rstatus |184| const,const,const |1|Using index condition| +----+-------------+-------+------+--------------------------+--------------------------+---------+-------------------+------+-----------------------+
rows
表示 MySQL 认为执行查询必须扫描的行数。
对于 InnoDB 表,此数字是估计值,可能并不总是准确。
当 prossible_keys 存在多个可选索引时,优化器会选择一个认为最优的执行方案,以最小的代价去执行语句。其中,这个扫描行数就是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的 IO 次数越少,消耗的 CPU 资源也越少。
EXPLAIN output shows Using index condition in the Extra column when Index Condition Pushdown is used. It does not show Using index because that does not apply when full table rows must be read.
ICP is used for the range, ref, eq_ref, and ref_or_null access methods when there is a need to access full table rows.
For InnoDB tables, ICP is used only for secondary indexes. The goal of ICP is to reduce the number of full-row reads and thereby reduce I/O operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce I/O.
…
ICP can reduce the number of times the storage engine must access the base table and the number of times the MySQL server must access the storage engine.
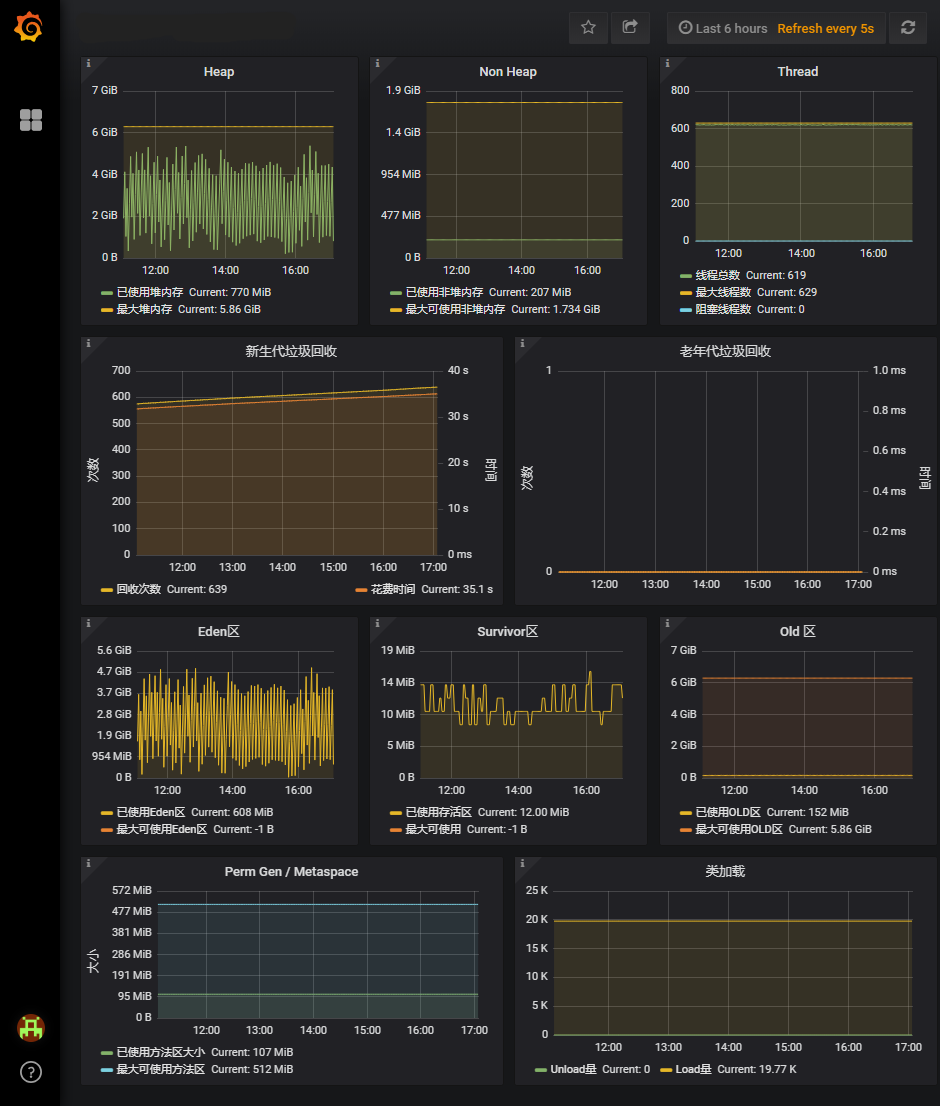
You use the jconsole command to start a graphical console to monitor and manage Java applications. JDK 5 起免费提供。一款基于 JMX (Java Management Extensions) 的可视化监视、管理工具。它的主要功能是通过 JMX 的 MBean (Managed Bean) 对系统进行信息收集和参数动态调整。
Integration of the Visual GC tool into VisualVM. Visual GC user interface is displayed for each local or remote application with performance counters available via jvmstat API.
The Visual GC tool attaches to an instrumented HotSpot JVM and collects and graphically displays garbage collection, class loader, and HotSpot compiler performance data.
Threads Inspector
Threads Inspector adds a new section to the Threads tab showing stack traces for the selected live threads.
TDA Plugin
Thread Dump Analyzer is a GUI for analyzing thread dumps generated by the Java VM.
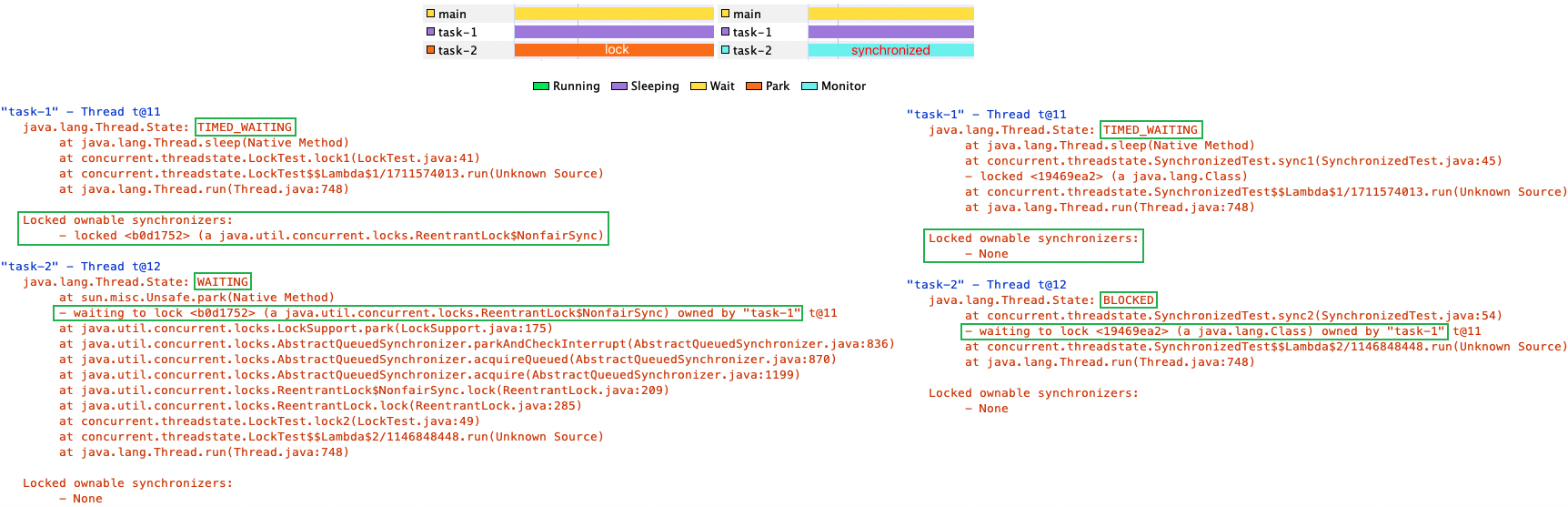
You use the jstack command to print Java stack traces of Java threads for a specified Java process. 显示虚拟机当前时刻的线程快照(thread dump/javacore 文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成堆栈快照的目的通常是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间挂起等,都是导致线程长时间停顿的常见原因。
You use the jmap command to print details of a specified process. 用于实时生成 JVM 堆内存转储快照(heap dump/hprof 文件),或查看堆内存信息。其它转储方法: -XX:+HeapDumpOnOutOfMemoryError -XX:+HeapDumpOnCtrlBreak
"catalina-exec-8000" daemon prio=10 tid=0x00007f67ba4a0000 nid=0x795a waiting on condition [0x00007f6558c0a000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007886ab360> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2043) at org.apache.http.pool.PoolEntryFuture.await(PoolEntryFuture.java:139) at org.apache.http.pool.AbstractConnPool.getPoolEntryBlocking(AbstractConnPool.java:307) at org.apache.http.pool.AbstractConnPool.access$000(AbstractConnPool.java:65) at org.apache.http.pool.AbstractConnPool$2.getPoolEntry(AbstractConnPool.java:193) at org.apache.http.pool.AbstractConnPool$2.getPoolEntry(AbstractConnPool.java:186) at org.apache.http.pool.PoolEntryFuture.get(PoolEntryFuture.java:108) at org.apache.http.impl.conn.PoolingClientConnectionManager.leaseConnection(PoolingClientConnectionManager.java:212) at org.apache.http.impl.conn.PoolingClientConnectionManager$1.getConnection(PoolingClientConnectionManager.java:199) at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:424) at org.apache.http.impl.client.AbstractHttpClient.doExecute(AbstractHttpClient.java:884) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:107) at com.xxx.xxx.xxx.HttpClientService.doPost(HttpClientService.java:103) ......
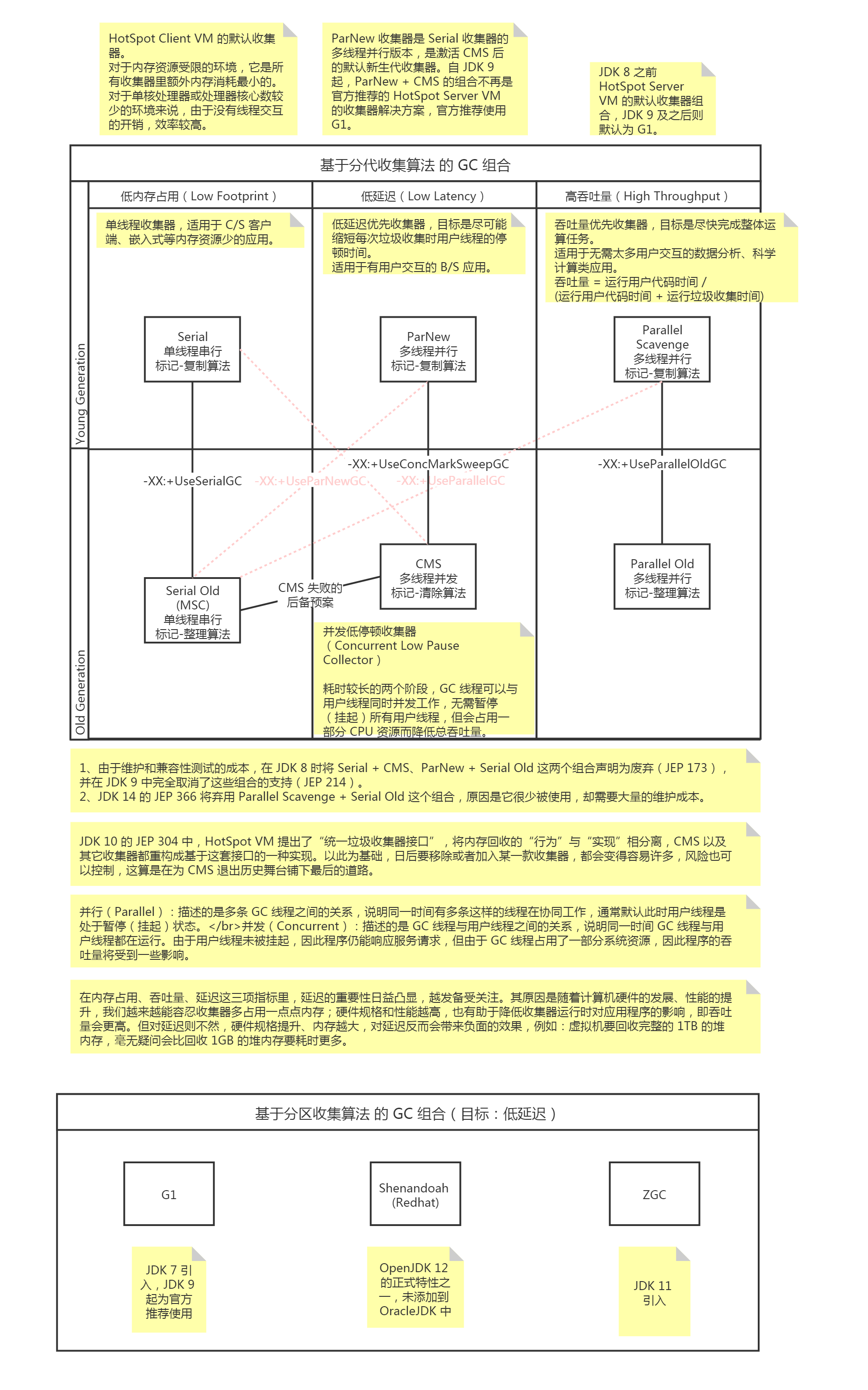
DefNew – single-threaded mark-copy stop-the-world garbage collector and is what is used to clean the Young generation(单线程 (single-threaded), 采用标记-复制 (mark-copy) 算法的,使整个 JVM 暂停运行 (stop-the-world) 的新生代 (Young generation) 垃圾收集器 (garbage collector))
Advanced Garbage Collection Options
GC Configuration
Description
-XX:+UseSerialGC
Serial + Serial Old
Enables the use of the serial garbage collector. This is generally the best choice for small and simple applications that do not require any special functionality from garbage collection. By default, this option is disabled and the collector is chosen automatically based on the configuration of the machine and type of the JVM.
-XX:+UseParNewGC
ParNew + SerialOld
Enables the use of parallel threads for collection in the young generation. By default, this option is disabled. It is automatically enabled when you set the -XX:+UseConcMarkSweepGC option. Using the -XX:+UseParNewGC option without the -XX:+UseConcMarkSweepGC option was deprecated in JDK 8.
Enables the use of the CMS garbage collector for the old generation. Oracle recommends that you use the CMS garbage collector when application latency requirements cannot be met by the throughput (-XX:+UseParallelGC) garbage collector. The G1 garbage collector (-XX:+UseG1GC) is another alternative. By default, this option is disabled and the collector is chosen automatically based on the configuration of the machine and type of the JVM. When this option is enabled, the -XX:+UseParNewGC option is automatically set and you should not disable it, because the following combination of options has been deprecated in JDK 8: -XX:+UseConcMarkSweepGC -XX:-UseParNewGC. (Serial + CMS)
Enables the use of the parallel scavenge garbage collector (also known as the throughput collector) to improve the performance of your application by leveraging multiple processors. By default, this option is disabled and the collector is chosen automatically based on the configuration of the machine and type of the JVM. If it is enabled, then the -XX:+UseParallelOldGC option is automatically enabled, unless you explicitly disable it.
Enables the use of the parallel garbage collector for full GCs. By default, this option is disabled. Enabling it automatically enables the -XX:+UseParallelGC option.
-XX:+UseG1GC
Enables the use of the garbage-first (G1) garbage collector. It is a server-style garbage collector, targeted for multiprocessor machines with a large amount of RAM. It meets GC pause time goals with high probability, while maintaining good throughput. The G1 collector is recommended for applications requiring large heaps (sizes of around 6 GB or larger) with limited GC latency requirements (stable and predictable pause time below 0.5 seconds). By default, this option is disabled and the collector is chosen automatically based on the configuration of the machine and type of the JVM.
Sets the thread stack size (in bytes). Append the letter k or K to indicate KB, m or M to indicate MB, g or G to indicate GB. The default value depends on the platform:
Linux/ARM (32-bit): 320 KB
Linux/i386 (32-bit): 320 KB
Linux/x64 (64-bit): 1024 KB
OS X (64-bit): 1024 KB
Oracle Solaris/i386 (32-bit): 320 KB
Oracle Solaris/x64 (64-bit): 1024 KB
The following examples set the thread stack size to 1024 KB in different units:
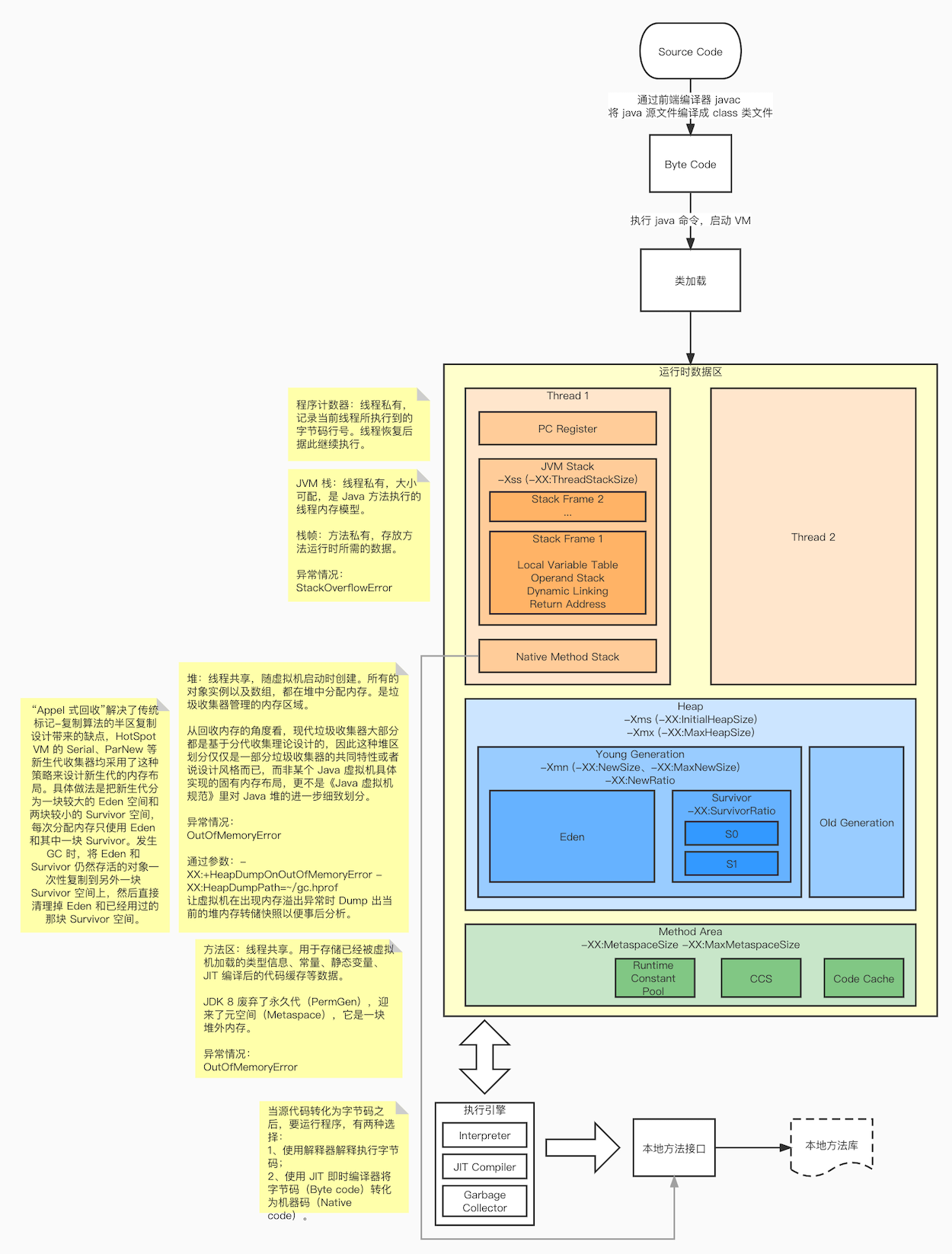
设置 Heap 堆内 Young Generation,而 Old Generation 等于:堆区减去 -Xmn。 设置 -Xmn 等同于设置了相同的 Young Generation 初始值 -XX:NewSize 和最大值 -XX:MaxNewSize。
参数
描述
-XX:NewRatio
Sets the ratio between young and old generation sizes. By default, this option is set to 2 (Young Gen can get up to 1/3 (Y=H/(R+1)) of the Heap).
-XX:SurvivorRatio
Sets the ratio between eden and survivor space sizes. By default, this option is set to 8 (S0/S1 can get up to 1/10 (S=Y/(R+2)) of Young Gen).
-Xms、-Xmx
-Xmssize
Sets the initial size (in bytes) of the heap. This value must be a multiple of 1024 and greater than 1 MB. Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes.
The following examples show how to set the size of allocated memory to 6 MB using various units:
1 2 3
-Xms6291456 -Xms6144k -Xms6m
If you do not set this option, then the initial size will be set as the sum of the sizes allocated for the old generation and the young generation.
The -Xms option is equivalent to -XX:InitialHeapSize.
-Xmxsize
Specifies the maximum size (in bytes) of the memory allocation pool in bytes. This value must be a multiple of 1024 and greater than 2 MB. Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes. The default value is chosen at runtime based on system configuration.
The following examples show how to set the maximum allowed size of allocated memory to 80 MB using various units:
1 2 3
-Xmx83886080 -Xmx81920k -Xmx80m
The -Xmx option is equivalent to -XX:MaxHeapSize.
-Xmn
-Xmnsize
Sets the initial and maximum size (in bytes) of the heap for the young generation (nursery).
The young generation region of the heap is used for new objects. GC is performed in this region more often than in other regions.
If the size is too small, then a lot of minor garbage collections will be performed.
If the size is too large, then only full garbage collections will be performed, which can take a long time to complete.
⚠️ Oracle recommends that you keep the size for the young generation between a half and a quarter of the overall heap size.
Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes. The following examples show how to set the initial and maximum size of young generation to 256 MB using various units:
1 2 3
-Xmn256m -Xmn262144k -Xmn268435456
Instead of the -Xmn option to set both the initial and maximum size of the heap for the young generation, you can use -XX:NewSize to set the initial size and -XX:MaxNewSize to set the maximum size.
-XX:NewRatio
-XX:NewRatio=ratio
Sets the ratio between young and old generation sizes. By default, this option is set to 2.
The NewRatio is the ratio of old generation to young generation (e.g. value 2 means max size of old will be twice the max size of young, i.e. young can get up to 1/3 of the heap).
1
Y=H/(R+1)
设置 Young Generation 和 Old Generation 的比值,例如该值默认为 2,则表示 Young Generation 和 Old Generation 比值为1:2。
-XX:SurvivorRatio
-XX:SurvivorRatio=ratio
Sets the ratio between eden and survivor space sizes. By default, this option is set to 8.
The following formula can be used to calculate the initial size of survivor space (S) based on the size of the young generation (Y), and the initial survivor space ratio (R):
1
S=Y/(R+2)
The 2 in the equation denotes two survivor spaces. The larger the value specified as the initial survivor space ratio, the smaller the initial survivor space size.
By default, the initial survivor space ratio is set to 8. If the default value for the young generation space size is used (2 MB), the initial size of the survivor space will be 0.2 MB.
The proposed implementation will allocate class meta-data in native memory and move interned Strings and class static variables to the Java heap.
Hotspot will explicitly allocate and free the native memory for the class meta-data. Allocation of new class meta-data would be limited by the amount of available native memory rather than fixed by the value of -XX:MaxPermSize, whether the default or specified on the command line.
Sets the maximum total size (in bytes) of the New I/O (the java.nio package) direct-buffer allocations. Append the letter k or K to indicate kilobytes, m or M to indicate megabytes, g or G to indicate gigabytes. By default, the size is set to 0, meaning that the JVM chooses the size for NIO direct-buffer allocations automatically.
The following examples illustrate how to set the NIO size to 1024 KB in different units: