GSLB(Global Server Load Balance,全局负载均衡)作为 CDN 系统架构中最核心的部分,负责流量调度。本文站在服务提供方的视角,做一些技术总结。
GSLB 横向对比
下表是三种常见的实现方式对比:
比较项
基于 DNS 解析方式
基于 HTTP 重定向方式
基于 IP 路由方式
性能
本地 DNS 服务器和用户终端 DNS 缓存能力使 GSLB 的负载得到有效分担
GSLB 处理压力大,容易成为系统性能的瓶颈
借助 IP 网络设备完成负载均衡,没有单点性能瓶颈
准确度
定位准确度取决于本地 DNS 覆盖范围,用户的本地 DNS 设置错误会造成定位不准确
在对用户 IP 地址数据进行有效维护的前提下,定位准确且精度高
就近性调度准确,但对设备健康性等动态信息响应会有延迟
效率
效率约等于 DNS 系统本身处理效率
依靠服务器做处理,对硬件资源的要求高
效率约等于 IP 设备本身效率
扩展性
扩展性和通用性好
扩展性较差,需对各种应用协议进行定制开发
通用性好,但适用范围有限
商用性
在 Web 加速领域使用较多
国内流媒体 CDN 应用较多
尚无商用案例
其中,基于 DNS 解析方式的 GSLB 有两个注意点:
准确度
本地 DNS 服务器(英文:Local DNS Server,缩写:LDNS)是用户所在局域网或 ISP 网络中使用的域名服务器,定位准确度就取决于它了。因为当用户在浏览器里访问某个域名时,浏览器会首先向 LDNS 发起查询,LDNS 再代为向整个 DNS 域名系统发起查询,直到找到解析结果。域名解析流程详见本文。
DNS 的查询机制给使用它的互联网应用带来额外的时延,有时时延还比较大,为了解决问题,引入了“缓存”机制。缓存是指 DNS 查询结果在 LDNS 中缓存,当其它主机向它发起查询请求时,它就直接向主机返回缓存中能够找到的结果,直到数据过期。
在基于 DNS 解析方式下无论采用何种工作方式,都会有一些请求不会到达 GSLB,这是 DNS 系统本身的缓存机制在起作用。当用户请求的域名在本地 DNS 或本机(客户端浏览器)得到了解析结果,这些请求就不会达到 GSLB。Cache 更新时间越短,用户请求到达 GSLB 的几率越大。由于 DNS 的缓存机制屏蔽掉相当一部分用户请求,从而大大减轻了 GSLB 处理压力,使得系统抗流量冲击能力显著提升,这也是很多商业 CDN 选择 DNS 机制做全局负载均衡的原因之一。但弊端在于,如果在 DNS 缓存刷新间隔之内系统发生影响用户服务的变化,比如某个节点故障,某个链路拥塞等,用户依然会被调度到故障点去。
智能 DNS 实现浅析
基于 DNS 解析方式的 GSLB 的实现关键,就在于使 DNS “智能化”。简单来说,就是通过建立 IP 地址访问列表,判断用户的访问来源,以确定其访问节点的位置。下面浅析如何实现智能 DNS:
IP 地址收集策略
由于基于 DNS 解析方式的 CDN 使用 LDNS 进行寻址,因此我们只需要收集互联网上 DNS 服务器的 IP 地址。这样一来,收集的数量就会大大降低。为了更进一步缩小范围,一般使用 IP 地址加子网掩码的形式,如 123.175.0.0/16。在 IP 地址列表文件,就这么一行,却可以囊括很多 DNS 服务器。
IP 地址收集方法
除了可以跟第三方购买 IP 地址段之外,这里重点介绍下如何自行收集 IP 地址段。
ICANN —— 一个负责 IP 地址分配以及域名管理的机构,与之关联的五个 RIR 机构负责替 ICANN 分配与登记部分区域的 IP 地址段:
可见,亚太地区的 IP 地址由 APNIC 分配,访问这里可以知道在何处得到 IP 地址分配的有用信息。进入 FTP ,阅读 README 以了解该下载哪个文件以及文件的格式。下载 delegated-apnic-latest 文件,过滤出分配给中国大陆(CN)的 IP 地址。
然后可以通过 ICANN Lookup 或 CNNIC IP 地址注册信息查询系统查询这个地址段属于哪个运营商,但一次只能查询一个地址段,根本无法手工完成所有地址段的查询,因此推荐在 Linux 下使用 whois 命令以遍历的方式逐个查询,然后按关键字归类、去重、排序,按运营商产生几个独立的文件。如果各 IP 地址租用方未能按统一的标准在 APNIC 提交注册信息则需要特殊处理。
IP 地址列表使用
最后,将每个 IP 地址列表文件关联一个 Bind 的视图 View。定义视图的目的在于,当有来自某个文件所列 IP 范围内的客户发起查询请求时,使用本视图的区文件进行域名解析。通俗的说,就是让某个运营商线路的用户,去访问某个运营商机房的服务器。
使用 Vim 也有好几年了,虽然这款“编辑器之神”的学习曲线非常陡峭,但一旦上手将会极大提高文本编辑效率,因此值得投入精力学习。
此外,Vim 哲学早已走出编辑器范畴,渗透到各种工具,例如:
本文我将会从三个方面总结 Vim 的知识。
四种常用模式
Vim 效率之高的秘密,就在于它拥有多种“模式”。如果你已经习惯了 Windows 下的编辑器,这些模式在一开始会很违反你的使用直觉。因此学习 Vim 的第一件事,就是要习惯这些模式之间的切换。
Vim 共具有 6 种基本模式和 5 种派生模式,下面只介绍最常用的 4 个基本模式:
普通模式(NORMAL MODE)
Vim 启动后的默认模式。这正好和许多新用户期待的操作方式相反,因为大多数编辑器的默认模式为插入模式(就是一打开编辑器就可以开始码字)。
Vim 强大的编辑能力中很大部分是来自于其普通模式的命令(及组合)。在普通模式下,用户可以执行一般的编辑器命令,比如移动光标,删除文本等等。如果进一步学习各种各样的文本间移动/跳转命令和其它编辑命令,并且能够灵活组合使用的话,能够比那些没有模式的编辑器更加高效的进行文本编辑。
下面介绍普通模式下几类常用的快捷键:
移动命令
跨行移动:
快捷键
说明
hjkl
VIM allows using the cursor keys in order to move around. However, for a pure VIM experience you should stick to using ‘h’, ‘j’, ‘k’ and ‘l’. It’s considered more efficient since you don’t have to move your hand from the home row when you’re typing.
gg
到第一行
G
到最后一行
nG
到第 n 行
%
匹配括号移动,包括 () {} [](需要先把光标先移到括号上)
*
匹配光标当前所在的单词(# 反向)
当前行移动:
快捷键
说明
0
到行头($ 反向)
^
到本行第一个非 blank 字符的位置(所谓 blank 字符就是空格、tab、换行、回车等)
w
到下一个单词的开头(b 反向)
e
到下一个单词的结尾
f
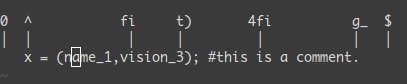
Find next character(F 反向) fi 到字符 i 处 4fi 到第四个字符 i 处
t
Find before character(T 反向)
编辑命令
文本替换:
快捷键
说明
r
Replace current character When you need to replace only one character under your cursor, without changing to insert mode, use r.
For each line in [range] replace a match of {pattern} with {string}.
详细命令:
1 2 3 4 5 6 7 8 9 10 11
4.2 Substitute *:substitute* *:s* *:su* :[range]s[ubstitute]/{pattern}/{string}/[flags] [count] For each line in [range] replace a match of {pattern} with {string}. For the {pattern} see |pattern|. {string} can be a literal string, or something special; see |sub-replace-special|. When [range] and [count] are omitted, replace in the current line only. When [count] is given, replace in [count] lines, starting with the last line in [range]. When [range] is omitted start in the current line. Also see |cmdline-ranges|. See |:s_flags| for [flags].
Sort lines in [range]. When no range is given all lines are sorted. With [!] the order is reversed. With [i] case is ignored. …
配置
使用 Vim 年月较久后总会定制一套个性化的 Vim 配置,例如截取一段常用的 ~/.vimrc 配置:
1 2 3 4 5 6 7 8 9 10 11 12 13
set number " 显示行号 set cursorline " 突出显示当前行 set ruler " 打开状态栏标尺 set shiftwidth=4 " 设定 << 和 >> 命令缩进时的宽度为 4 set softtabstop=4 " 使得按退格键时可以一次删掉 4 个空格 set tabstop=4 " 设定 tab 长度为 4 set nowrapscan " 禁止在搜索到文件两端时重新搜索 set incsearch " 输入搜索内容时就显示搜索结果 set hlsearch " 高亮显示搜索结果 syntax on " 程序语法开关 inoremap jj <ESC> " 重映射 ESCAPE 键 " 定义缩写:ab [缩写] [要替换的文字] ab asap as soon as possible
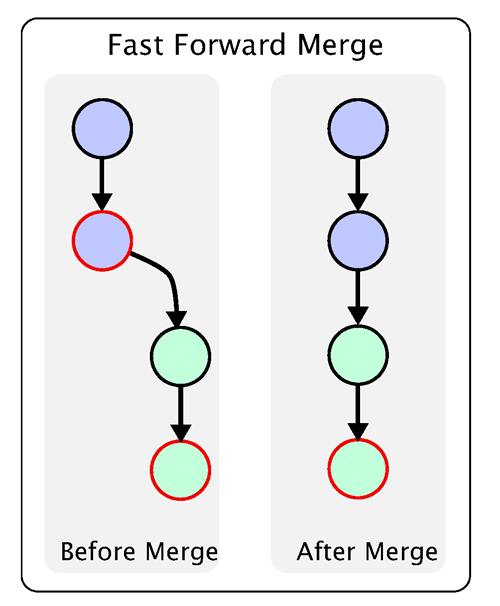
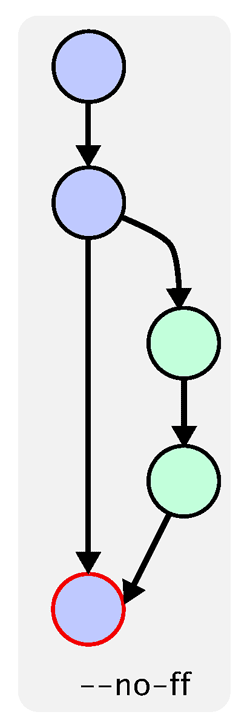
Merge tool is a GUI that steps you through each conflict, and you get to choose how to merge. Sometimes it requires a bit of hand editing afterwards, but usually it’s enough by itself. It is much better than doing the whole thing by hand certainly.
$ git pull error: Your local changes to the following files would be overwritten by merge: /there/is/a/conflict/file Please, commit your changes or stash them before you can merge.
Stashing takes the dirty state of your working directory – that is, your modified tracked files and staged changes – and saves it on a stack of unfinished changes that you can reapply at any time.
1 pick dc6baf3 本地分支提交的版本 2 pick 915fe84 先被推送到远程分支的版本 3 4 # Rebase 1ff20826..61527529 onto 1ff20826 (2 commands) 5 # 6 # Commands: 7 # p, pick = use commit 8 # r, reword = use commit, but edit the commit message 9 # e, edit = use commit, but stop for amending 10 # s, squash = use commit, but meld into previous commit 11 # f, fixup = like "squash", but discard this commit's log message 12 # x, exec = run command (the rest of the line) using shell 13 # d, drop = remove commit 14 # 15 # These lines can be re-ordered; they are executed from top to bottom. 16 # 17 # If you remove a line here THAT COMMIT WILL BE LOST. 18 # 19 # However, if you remove everything, the rebase will be aborted. 20 # 21 # Note that empty commits are commented out
$ git status Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
那么,对于已 add 进暂存区的文件,如何撤销本地修改?还是先使用 status 命令查看一下文件状态:
1 2 3 4 5
$ git status Changes to be committed: (use "git reset HEAD <file>..." to unstage)
modified: /there/is/a/modified/file
先取消暂存修改
Git 提示我们,可以使用 reset 命令取消暂存:
1
$ git reset /there/is/a/modified/file
取消暂存后,文件状态就回到了跟“例1”一样了:
1 2 3 4 5 6
$ git status Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
modified: /there/is/a/modified/file
再撤销本地修改
这时按提示使用 checkout 即可:
1
$ git checkout -- /there/is/a/modified/file
这时工作目录就干净了:
1 2
$ git status nothing to commit, working directory clean
可以看到,结合使用 reset 和 checkout 命令,可以撤销 index 和 working tree 的修改。
一步到位
那么有更便捷的、一步到位的办法吗?有,指定提交即可:
1 2 3 4 5
$ git status Changes to be committed: (use "git reset HEAD <file>..." to unstage)
modified: /there/is/a/modified/file
1
$ git checkout HEAD -- /there/is/a/modified/file
1 2
$ git status nothing to commit, working directory clean
那么 checkout 命令的全貌究竟是怎样的呢?
checkout 命令格式
checkout 命令的格式及描述如下:
1 2 3
git checkout [<tree-ish>] [--] <paths>...
Updates the named paths in the working tree from the index file (default) or from a named <tree-ish> (most often a commit, tag or branch)
This form copy entries from <tree-ish> to the index for all <paths>. (It does not affect the working tree or the current branch.)
与 checkout 命令的参数一模一样,区别是什么?
命令
操作目标
描述
checkout
工作目录(working tree)
用于撤销本地修改
reset
暂存区(index)
只用于覆盖暂存区
因此 git reset <paths> 等于 git add <paths> 的逆向操作。
如果企图用 reset 命令覆盖工作目录,是会报错的:
1 2
$ git reset --hard /there/is/a/modified/file fatal: Cannot do hard reset with paths.
关系
After running git reset <paths> to update the index entry, you can use git checkout -- <paths> to check the contents out of the index to the working tree.
Alternatively, using git checkout [<tree-ish>] [--] <paths> and specifying a commit, you can copy the contents of a path out of a commit to the index and to the working tree in one go.