MySQL JOIN 表连接总结
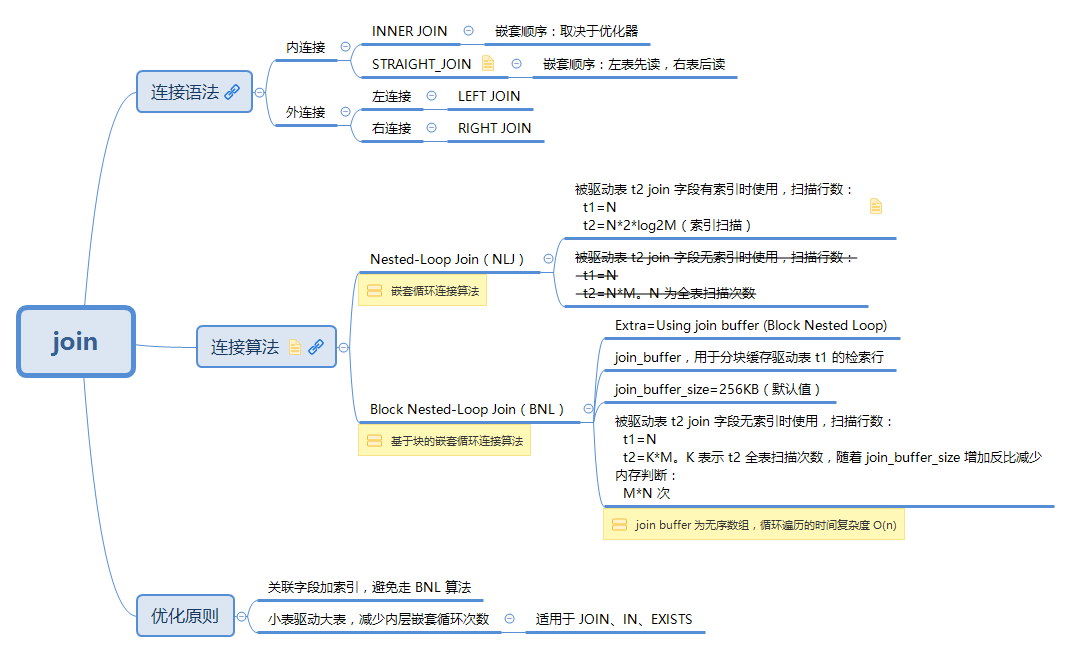
连接语法
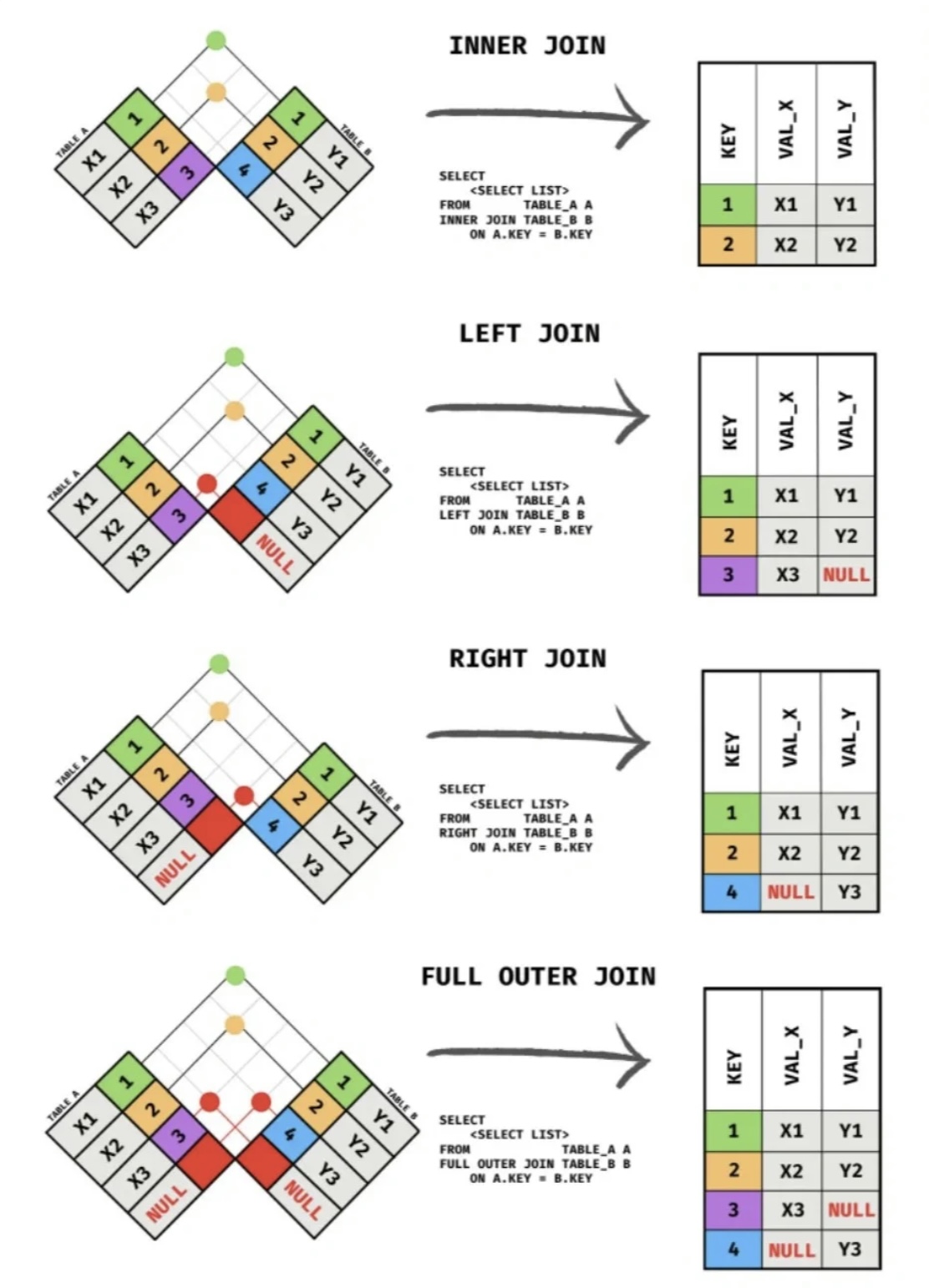
内连接
1 | # 简单的等值语法创建内联结 |
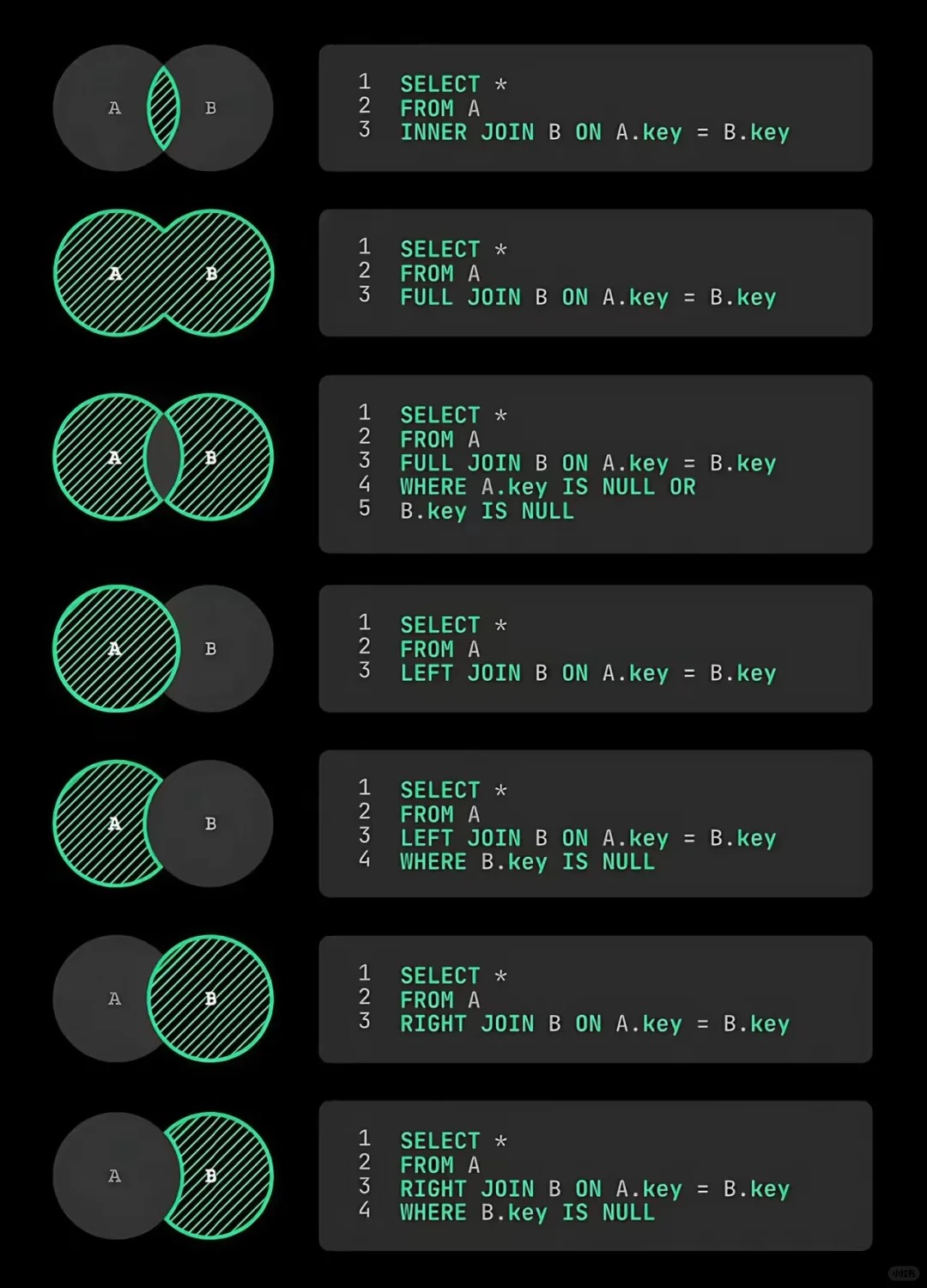
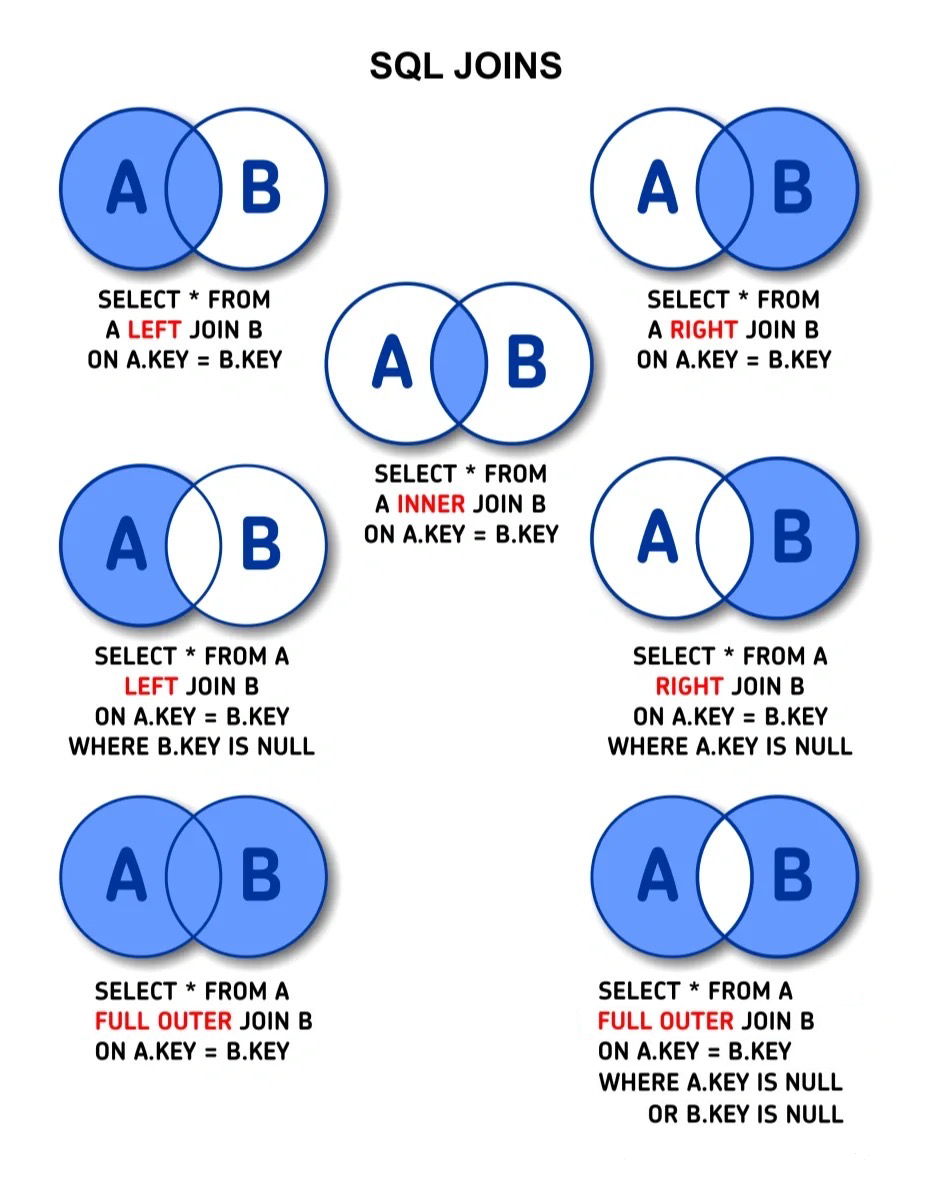
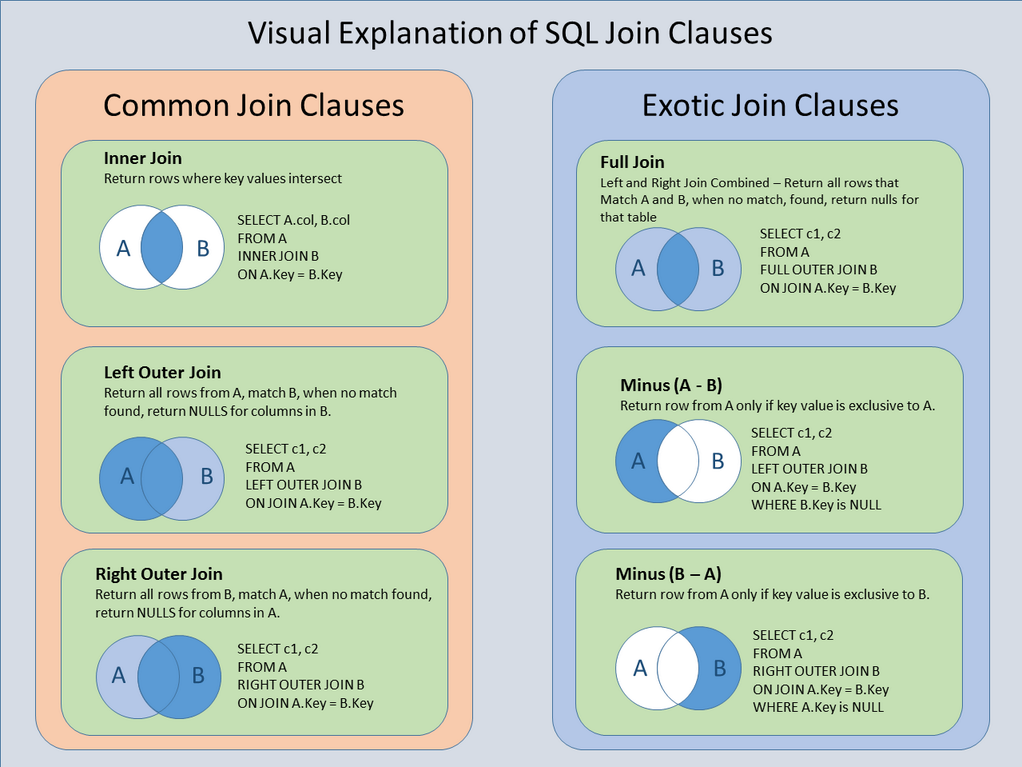
在内连接两个表时,实际要做的是将第一个表中的每一行与第二个表中的每一行配对,WHERE 或 ON 子句作为过滤条件,只包含那些匹配连接条件的行。
由没有连接条件的表关系返回的结果为笛卡儿积(cartesian product)。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。因此应当总是提供连接条件。
外连接(左、右)
许多连接将一个表中的行与另一个表中的行相关联,但有时候需要包含没有关联行的那些行,例如:
对每个顾客下的订单进行计数,包括那些至今尚未下订单的顾客;
列出所有产品以及订购数量,包括没有人订购的产品;
计算平均销售规模,包括那些至今尚未下订单的顾客。
在上述例子中,连接包含了那些在相关表中没有关联行的行。这种连接称为外连接。
例如,要检索出所有顾客+订单,包括那些还未下单的顾客:
1 | SELECT Customers.cust_id, Orders.order_num |
上例如果使用内连接,将不包含 1000000002 顾客,因为他还未下单(即连接条件不匹配)。
作为对比,下例使用内连接 INNER JOIN 和聚集函数 COUNT() 统计出所有顾客的订单数:
1 | SELECT Customers.cust_id, COUNT(Orders.order_num) AS num_ord |
但如果使用左外连接 LEFT OUTER JOIN 和聚集函数 COUNT() 进行相同统计,将会包括那些还未下单的顾客,例如顾客 1000000002:
1 | SELECT Customers.cust_id, COUNT(Orders.order_num) AS num_ord |
由于 COUNT(column) 计数会忽略 NULL 值,因此顾客 1000000002 的统计结果为 0。
注意,左、右外连接之间的唯一差别是所关联的表的顺序。换句话说,调整 FROM 或 WHERE 子句中表的顺序,左外连接可以转换为右外连接。因此,这两种外连接可以互换使用,哪个方便就用哪个。
连接算法
MySQL 使用下面两种算法执行表连接:
- 嵌套循环连接算法(Nested-Loop Join(NLJ)),在被驱动表
join字段有索引时使用。 - 基于块的嵌套循环连接算法(Block Nested-Loop Join(BNL)),在被驱动表
join字段无索引时使用,以减少被驱动表的全表扫描次数。
NLJ
Nested-Loop Join (NLJ) :
A simple nested-loop join (NLJ) algorithm reads rows from the first table in a loop one at a time, passing each row to a nested loop that processes the next table in the join. This process is repeated as many times as there remain tables to be joined.
例如,使用以下 join type 执行 t1、t2 和 t3 三个表之间的表连接:
1 | Table Join Type |
使用 NLJ 算法,则按以下方式处理连接:
1 | for each row in t1 matching range { |
BNL
BNL 算法将外层循环的检索行缓存到 join_buffer(无序数组)中,以减少内层循环的全表扫描次数。例如,如果外层循环先将 10 行数据读入缓冲区,并将其传递给下一个内层循环,内层循环只需全表扫描一次,即可将读取到的每一行与缓冲区中的所有 10 行在内存中进行比较。这将使得内层循环表的全表扫描次数减少一个数量级。
MySQL join buffer 具有以下特征:
- 当
join type为ALL、index、range使用join buffer。 join buffer同样适用于外连接,详见:Section 8.2.1.11, “Block Nested-Loop and Batched Key Access Joins”- 系统变量
join_buffer_size用于配置每次查询每个 BNL 连接的缓冲区大小,因此一个查询可能用到多个join buffer。 - 在执行连接之前分配
join buffer,并在查询完成后释放。
使用 BNL 算法,伪代码如下:
1 | for each row in t1 matching range { |
设 S 为每行 used columns from t1, t2 的大小, C 为其行数,则 t3 全表扫描的次数为:
1 | t3_scanned_count = |
因此,随着 join_buffer_size 增加,t3 全表扫描的次数反比减少,直到 join_buffer_size=(S * C) 时则无法再优化。