MySQL 索引优化总结
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高几个数量级,“最优”的索引有时比一个“好的”索引性能要好两个数量级。
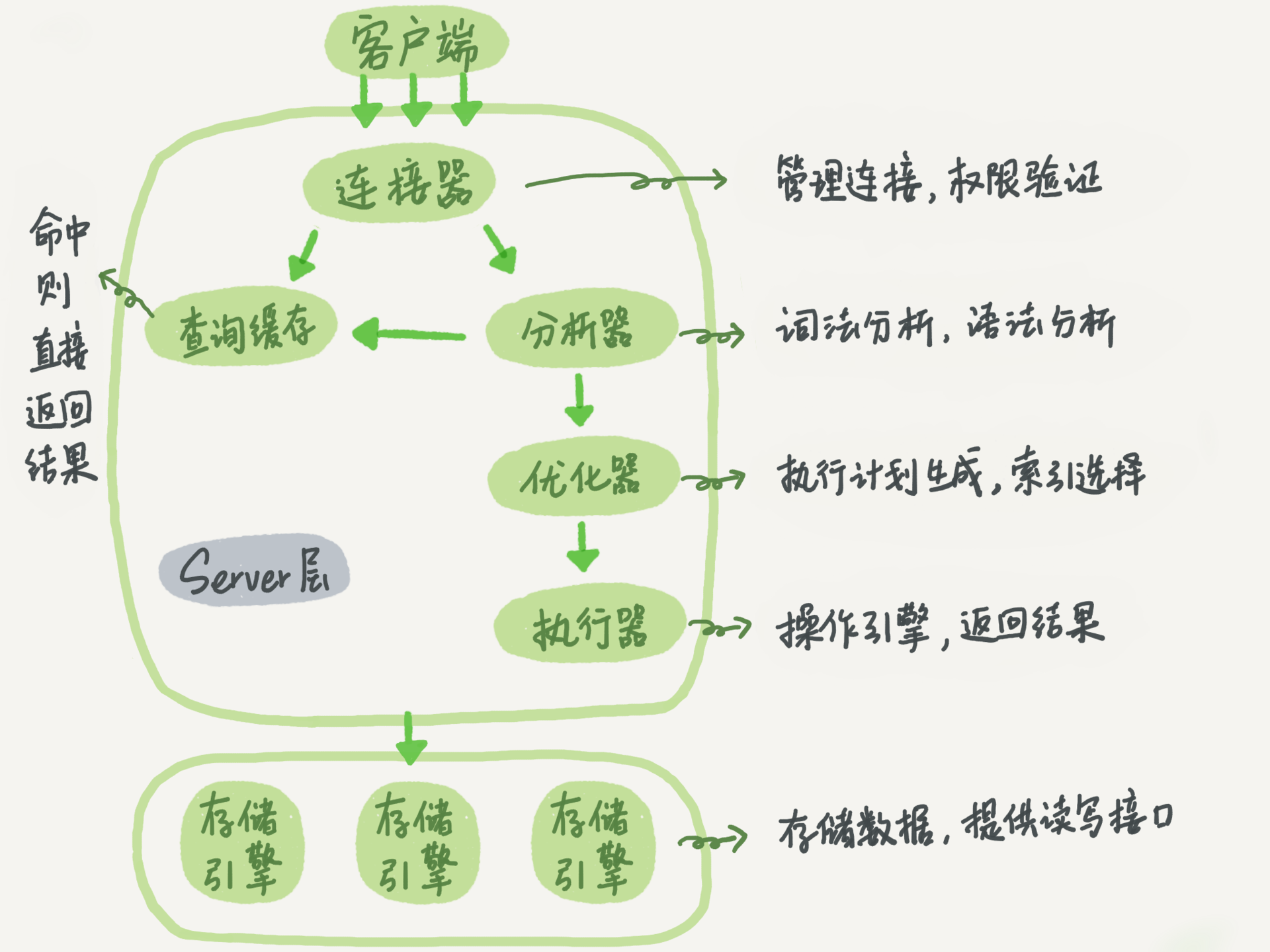
索引是存储引擎用于快速找到记录的一种数据结构。在 MySQL 中,索引是在存储引擎层而不是服务器层实现的(如下图)。所以,并没有统一的索引标准:不同存储引擎的索引的工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。
常见索引类型
MySQL 支持的常见索引类型:
- B+Tree 索引
- Hash index(哈希索引)
- R-Tree index(空间数据索引)
- Full-text index(全文索引)
- ……
本文只探讨最常用的 B-Tree 索引。
B+Tree 数据结构
B+Tree 索引特性
当我们谈论索引的时候,如果没有特别指明类型,那多半说的是 B+Tree 索引。InnoDB 存储引擎默认使用的也是 B+Tree 数据结构来存储数据。
索引可以包含一个或多个列的值。如果包含多个列(称为“联合索引”),那么列的顺序至关重要,因为 MySQL 只能高效地使用索引的 最左前缀列。创建一个包含两个列的索引,和创建两个只包含一列的索引是大不相同的,下面看个例子:
1 | CREATE TABLE People ( |
可以使用该 B-Tree 索引的查询类型:
全值匹配
全值匹配(Match the full value):
1 | SELECT * |
匹配最左前缀
匹配最左前缀(Match a leftmost prefix):
1 | SELECT * |
匹配列前缀
匹配列前缀(Match a column prefix):
1 | SELECT * |
注意 MySQL LIKE 的限制:
MySQL can’t perform the LIKE operation in the index. This is a limitation of the low-level storage engine API, which in MySQL 5.5 and earlier allows only simple comparisons (such as equality, inequality, and greater-than) in index operations.
MySQL can perform prefix-match LIKE patterns in the index because it can convert them to simple comparisons, but the leading wildcard in the query makes it impossible for the storage engine to evaluate the match. Thus, the MySQL server itself will have to fetch and match on the row’s values, not the index’s values.
匹配范围值
匹配范围值(Match a range of values):
1 | SELECT * |
精确匹配某一列,并范围匹配另外一列
精确匹配某一列,并范围匹配另外一列(Match one part exactly and match a range on another part):
1 | SELECT * |
覆盖索引
只访问索引列的查询(Index-only queries):
1 | SELECT last_name, first_name, dob |
高性能的索引策略
选择合适的索引列顺序
联合索引列按区分度从高到低排列。例如 idx(ctime_status) 而不是 idx(status_ctime)。
使用独立的列
“独立的列”是指不在索引列上做任何操作,包括:
- 计算(不能是表达式的一部分)
- 作为函数的参数
- 隐式或显式的类型转换(参考:https://zhuanlan.zhihu.com/p/30955365)
- 隐式字符编码转换
例如,下面这个查询无法使用 actor_id 列的索引:
1 | -- 错误示范 |
凭肉眼很容易看出 WHERE 中的表达式其实等价于 id = 4 ,但是 MySQL 无法自动解析这个方程式。这完全是用户行为。我们应该养成简化 WHERE 条件的习惯,始终将索引列单独放在比较符号的一侧。
下面是另一个常见的错误,将索引列作为函数的参数:
1 | -- 错误示范 |
另一个常见错误,merchant_no 为 VARCHAR 类型且加了索引,但由于隐式类型转换为数字类型,导致全表扫描:
1 | -- 错误示范 |
字符串索引优化
常规方式
- 直接创建完整索引
- 优点:可以使用覆盖索引
- 缺点:比较占用空间
- 创建前缀索引
- 优点:节省空间
- 缺点:
- 需要计算好区分度,以定义合适的索引长度,否则会增加回表次数
- 无法使用覆盖索引
区分度计算方法:
1 | select |
其它方式一
- 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题。查询时使用
reverse函数。 - 创建额外的 hash 字段并创建索引,查询性能稳定(散列冲突的概率更小),有额外的存储和计算消耗,查询时使用
crc32函数并二次比较。
这两种方式都不支持范围扫描,只支持等值查询。
其它方式二
改为使用更合适的数据类型,例如:
- 使用日期与时间类型,而不是字符串来存储日期和时间。
- 使用整型,而不是字符串来存储 IP 地址。
- 使用定长二进制类型(如
binary),而不是字符串来存储散列值。
索引选择性
了解两个概念:
- 基数(Cardinality)也称为区分度,是指数据列所包含的不同值的数量。例如,某个数据列包含值:1、2、3、4、5、1,则基数为 5。可以通过
show index查看。 - 索引选择性(Index Selectivity)是指基数(Cardinality)和数据表的记录总数(#T)的比值,范围从
1/#T到1之间。
索引的选择性越高则查询效率越高,因为选择性高的索引可以让 MySQL 在查找时过滤掉更多的行。唯一索引的选择性是 1,这是最好的索引选择性,性能也是最好的。
下面显示如何计算某列的平均选择性:
1 | SELECT COUNT(DISTINCT last_name) / COUNT(*) AS Selectivity |
只看平均选择性有时是不够的,需考虑最坏或特殊情况下的选择性(即值的分布,是否有某些值占比过多?)。
如果索引的选择性低(基数/总数的比值),可能会导致优化器生成执行计划时,不走这个索引。
有时 MySQL 会选错索引,解决方案如下:
- 通过
show index语句查看索引的“基数”。对于由于索引统计信息不准确导致的问题,可以用analyze table来重新统计索引信息。 force index强行选择一个索引。- 修改语句,引导 MySQL 使用我们期望的索引。
- 新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
三星索引评价系统
评估某个索引是否适合某个查询的“三星评价系统”(three-star system):
Lahdenmaki and Leach’s book also introduces a three-star system for grading how suitable an index is for a query:
- The index earns one star if it places relevant rows adjacent to each other,
- a second star if its rows are sorted in the order the query needs,
- and a final star if it contains all the columns needed for the query.
- 一星:索引列满足查询所需的条件。如果是多个查询条件,则利用联合索引及其最左前缀匹配特性。
- 二星:索引行排序符合查询所需的排序,没有额外的
ORDER BY(避免filesort)。 - 三星:索引列满足查询所需的全部列,不再需要回表查询(即利用覆盖索引
covering index)。
相关命令
下面介绍一些查看索引的常用命令:
DESC
DESC 命令查看表结构时,可以看到索引列 Key ,共有三种类型:
PRI表示主键索引(PRIMARY KEY)。UNI表示唯一索引(UNIQUE KEY),值不能重复。MUL表示普通索引(MULTIPLE KEY) ,值可重复。
1 | $ DESC table_name; |
SHOW INDEX
SHOW INDEX 可以以列为单位,查看该表索引的具体信息,例如:
- 表名
Table - 索引唯一性
Non_unique - 索引名
Key_name - 联合索引中的顺序
Seq_in_index - 列名
Column_name - 基数
Cardinality - 索引类型
Index_type
1 | $ SHOW INDEX FROM table_name; |
SHOW CREATE TABLE
SHOW CREATE TABLE 可以查看该表的建表语句,留意最后几行:
1 | SHOW CREATE TABLE table_name; |
参考
《高性能 MySQL》
https://dev.mysql.com/doc/refman/5.7/en/innodb-indexes.html
https://dev.mysql.com/doc/refman/5.7/en/optimization-indexes.html