响应式编程系列(二)Reactor 框架入门总结
响应式编程
响应式编程,如 Reactor 旨在解决 JVM 上传统异步编程带来的缺点、以及编程范式上从命令式过渡到响应式编程:
阻塞带来的性能浪费
现代的应用程序通常有大量并发请求。即使现代的硬件性能不断提高,软件性能仍然是关键瓶颈。
广义上讲,有两种方法可以提高程序的性能:
- 利用并行(parallel)使用更多 CPU 线程和更多硬件资源。
- 提升现有资源的利用率。
通常,Java 开发者使用阻塞方式来编写程序。除非达到性能瓶颈,否则这种做法可行。之后,通过增加线程数,运行类似的阻塞代码。 但这种方式很快就会导致资源争用和并发问题。
更糟糕的是,阻塞会浪费资源。试想一下,程序一旦遇到一些延迟(特别是 I/O 操作,例如数据库请求或网络请求),就会挂起线程,从而导致资源浪费,因为大量线程处于空闲状态,等待数据,甚至导致资源耗尽。尽管使用池化技术可以提升资源利用率、避免资源耗尽,但只能缓解而不能解决根本问题,而且池内资源同样有耗尽的问题。
因此,并行技术并非银弹。
传统异步编程带来的缺点
Java 提供了两种异步编程模型:
- Callbacks: 异步方法没有返回值,但是带有一个额外的
callback回调参数(值为 Lambda 表达式或匿名类),回调参数在结果可用时被调用。 - Futures: 异步方法调用后立即返回一个
Future<T>对象。异步方法负责计算出结果值T,由Future对象包装起来。该结果值并非立即可用,可以轮询该Future对象,直到结果值可用为止。这种方式顺序执行代码,将异步编程模型转为同步编程模型。ExecutorService提供了方法<T> Future<T> submit(Callable<T> task)。
两种模型都有一个共同的缺点:难以组合代码,从而导致代码可读性差、难以维护。例如,当业务逻辑复杂,步骤存在依赖关系时,会导致回调嵌套过深,从而导致著名的 Callback Hell 问题。
详见代码例子。
从命令式过渡到响应式编程

Reactor 框架
Reactor 是一款基于 JVM 的完全非阻塞的响应式编程框架。它实现了 Reactive Streams 规范,具有高效的流量控制(以管理背压的形式),并扩展了大量特性,例如提供了丰富的 Operators 运算符。
先决条件
Reactor Core 需要在 Java 8 及以上版本运行。因为 Reactor 直接集成了 Java 8 的函数式 API,特别是:
java.util.CompletableFuturejava.util.stream.Streamjava.time.Duration
依赖安装
自 Reactor 3 开始(since reactor-core 3.0.4, with the Aluminium release train),Reactor 使用 BOM (Bill of Materials) 模型来管理依赖。BOM 将一组相关的、可以良好协作的构建(Maven Artifact)组合在一起,提供版本管理。避免构件间潜在的版本不兼容风险。
为项目引入该 BOM:
1 | <dependencyManagement> |
然后就可以为项目添加相关依赖。注意忽略版本号,以便由 BOM 统一管理版本号(除非你想覆盖 BOM 管理的版本号):
1 | <dependencies> |
这里 Reactor Core 传递依赖于 Reactive Stream 规范,如下:
1 | <dependency> |
API
Reactor Core 提供了两个可组合式的异步串行 API:
reactor.core.publisher.Mono(for [0|1] elements)reactor.core.publisher.Flux(for [N] elements)
这两个类都是 org.reactivestreams.Publisher 接口的实现类:
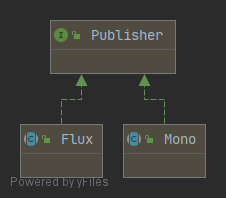
Reactor Core 还提供了 org.reactivestreams.Subscriber 接口的实现类,如下(还有其它子类,此处不一一例举):

LambdaSubscriber 的构造方法如下:

不过一般不会直接使用该实现类,而是使用 Mono、Flux 提供的 subscribe 方法(如下图),并传入 Lambda 表达式语句(代码即参数),由方法的实现负责将参数封装为 Subscriber 接口的实现类,供消费使用:

参考
Reactor 框架,实现 Reactive Streams 规范,并扩展大量特性