背景 为什么要用线程池?
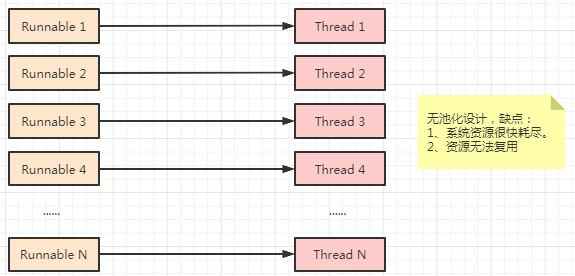
线程的创建和销毁是有代价的。
如果请求的到达率非常高且请求的处理过程是轻量级的,那么为每个请求创建一个新线程将消耗大量的计算资源。
活跃的线程会消耗系统资源,尤其是内存。大量空闲线程会占用许多内存,给垃圾回收器带来压力,而且大量线程竞争 CPU 资源还会产生其它的性能开销。
可创建线程的数量上存在限制,如果创建太多线程,会使系统饱和甚至抛出 OutOfMemoryException 。
问题如下:
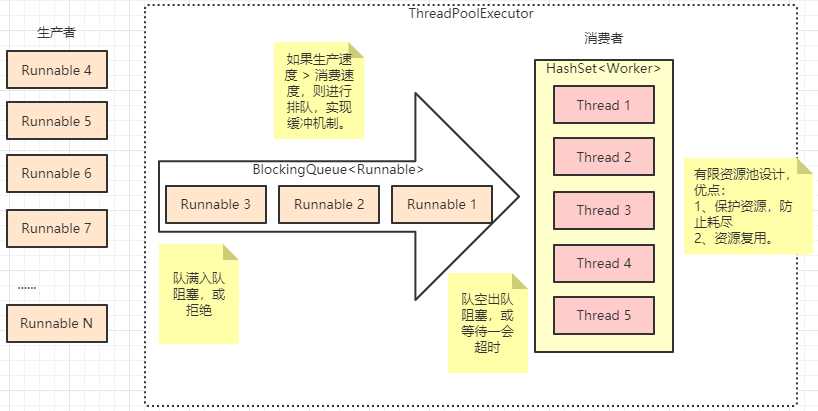
为了解决以上问题,从 Java 5 开始 JDK 并发 API 提供了 Executor Framework,用于将任务的创建与执行分离 ,避免使用者直接与 Thread 对象打交道,通过池化设计与阻塞队列保护系统资源:
使用 Executor Framework 的第一步就是创建一个 ThreadPoolExecutor 类的对象。你可以使用这个类提供的 四个构造方法 或 Executors 工厂类 来创建 ThreadPoolExecutor 。一旦有了执行器,你就可以提交 Runnable 或 Callable 对象给执行器来执行。
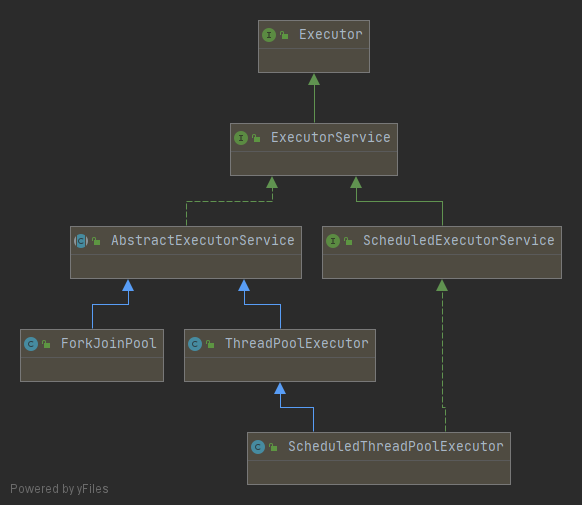
自定义线程池 继承关系 Executor 接口的实现类如下:
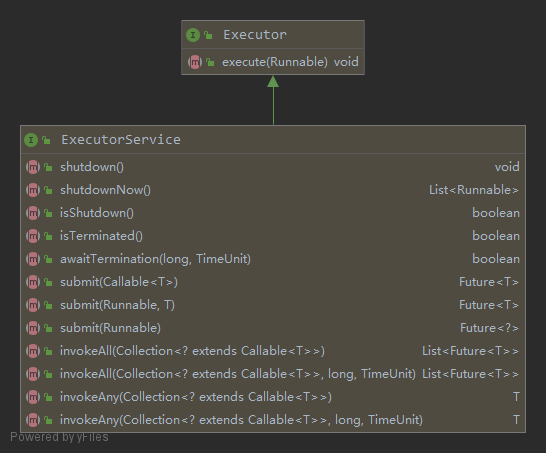
其中,ThreadPoolExecutor 类实现了两个核心接口 Executor 和 ExecutorService,方法如下:
成员变量 ThreadPoolExecutor 类的成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 private final AtomicInteger ctl = new AtomicInteger (ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;private static int runStateOf (int c) { return c & ~CAPACITY; }private static int workerCountOf (int c) { return c & CAPACITY; }private static int ctlOf (int rs, int wc) { return rs | wc; }private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;private final ReentrantLock mainLock = new ReentrantLock ();private final HashSet<Worker> workers = new HashSet <Worker>();private final Condition termination = mainLock.newCondition();private int largestPoolSize;private long completedTaskCount; private volatile int corePoolSize; private volatile int maximumPoolSize;private volatile long keepAliveTime;private volatile boolean allowCoreThreadTimeOut;private volatile ThreadFactory threadFactory;private final BlockingQueue<Runnable> workQueue;private volatile RejectedExecutionHandler handler;private static final RejectedExecutionHandler defaultHandler = new AbortPolicy (); private static final RuntimePermission shutdownPerm = new RuntimePermission ("modifyThread" );
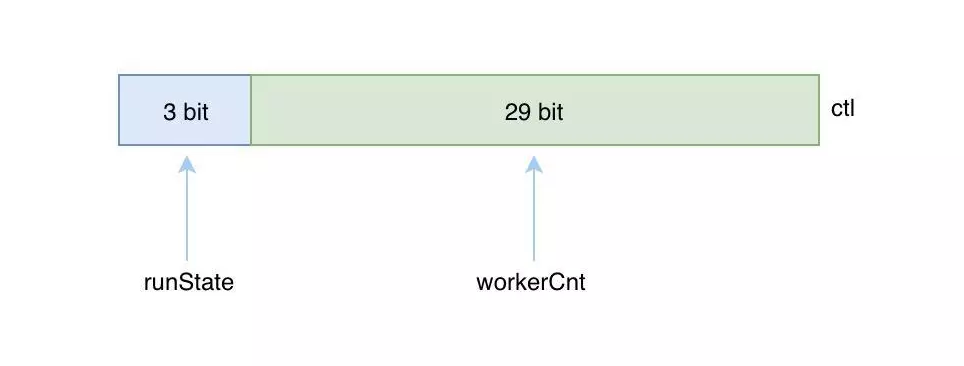
ctl 作为一个线程池,首先有两个关键属性:
线程池状态 runState
工作线程数 workerCnt
这两个关键属性保存在名为 ctl 的 AtomicInteger 类型属性之中,高 3 位表示 runState,低 29 位表示 workerCnt,如下:
为什么要用 3 位来表示线程池的状态呢,原因是线程池一共有 5 种状态,而 2 位只能表示出 4 种情况,所以至少需要 3 位才能表示得了 5 种状态,如下:
1 2 3 4 5 6 7 runState workerCnt runState workerCnt 000 00000000000000000000000000000 SHUTDOWN empty 001 00000000000000000000000000000 STOP empty 010 00000000000000000000000000000 TIDYING empty 011 00000000000000000000000000000 TERMINATED empty 111 00000000000000000000000000000 RUNNING empty 111 11111111111111111111111111111 RUNNING full
通过 ctlOf 方法初始化 ctl 属性:
1 2 3 4 5 6 7 8 9 10 11 private static int ctlOf (int rs, int wc) { return rs | wc; } 11100000000000000000000000000000 | 00000000000000000000000000000000 = 11100000000000000000000000000000
通过 runStateOf 方法获取线程池状态 runState:
1 2 3 4 5 6 7 8 9 10 private static int runStateOf (int c) { return c & ~CAPACITY; } ~11111111111111111111111111111 = 00000000000000000000000000000 & 111 11111111111111111111111111111 = 111
通过 workerCountOf 方法获取工作线程数 workerCnt:
1 2 3 4 5 6 7 8 9 10 11 private static int workerCountOf (int c) { return c & CAPACITY; } 111 11111111111111111111111111111 & 11111111111111111111111111111 = 11111111111111111111111111111
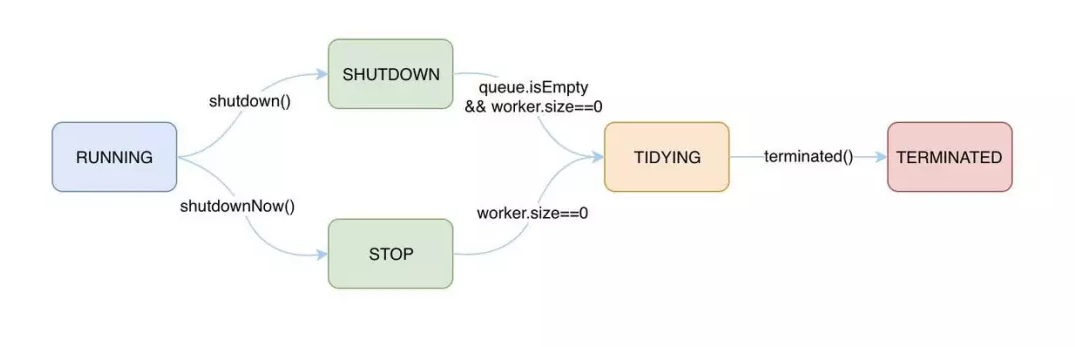
线程池状态 线程池状态用于标识线程池内部的一些运行情况,线程池的开启到关闭的过程就是线程池状态的一个流转的过程。
线程池共有五种状态:
状态
runState含义
RUNNING111
运行状态,该状态下线程池可以接受新的任务,也可以处理阻塞队列中的任务。shutdown 方法可进入 SHUTDOWN 状态。shutdownNow 方法可进入 STOP 状态。
SHUTDOWN000
待关闭状态,不再接受新的任务,继续处理阻塞队列中的任务。TIDYING 状态。
STOP001
停止状态,不接收新任务,也不处理阻塞队列中的任务,并且会尝试结束执行中的任务。TIDYING 状态。
TIDYING010
整理状态,此时任务都已经执行完毕,并且也没有工作线程 执行 terminated 方法后进入 TERMINATED 状态。
TERMINATED011
终止状态,此时线程池完全终止了,并完成了所有资源的释放。
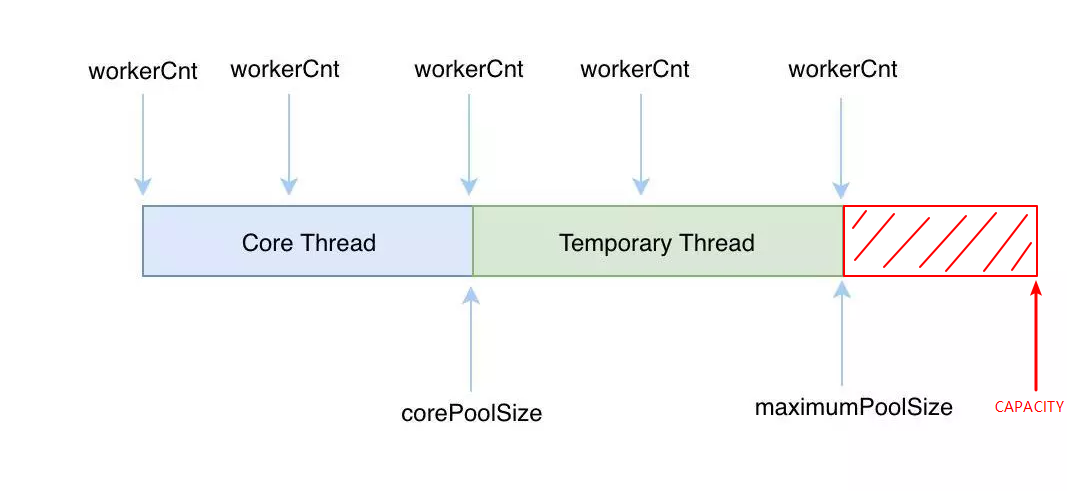
工作线程数 尽管理论上线程池最大线程数量可达 CAPACITY 数,但是实际上都会通过 maximumPoolSize 限制最大线程数。因此工作线程数 workerCnt 的个数可能在 0 至 maximumPoolSize 之间变化。
当工作线程的空闲时间达到 keepAliveTime,该工作线程会退出,直到工作线程数 workerCnt 等于 corePoolSize。如果 allowCoreThreadTimeout 设置为 true,则所有工作线程均会退出。
注意:
整个线程池的基本执行过程:创建核心线程(Core Thread) > 任务排队 > 创建临时线程(Temp Thread)。
如果将 maximumPoolSize 设置为无界值(如 Integer.MAX_VALUE),可能会创建大量的线程,从而导致 OOM。因此务必要限定 maximumPoolSize 的大小。
如果将 corePoolSize 和 maximumPoolSize 设置为相同值,则创建了 Fixed 固定大小的线程池,无法弹性扩容,只能排队。
线程工厂 通过提供不同的 ThreadFactory 接口实现,可以定制被创建线程 Thread 的属性 。ThreadFactory 有几种创建方式:
1、完全自定义方式。缺点是需要在 newThread 方法中实现的代码较多:
1 2 3 4 5 6 7 8 ThreadFactory threadFactory = runnable -> { Thread t = new Thread (runnable); t.setName("wechat-notify-1" ); t.setDaemon(false ); t.setPriority(1 ); t.setUncaughtExceptionHandler((thread, exception) -> {}); return t; };
2、使用 Executors 工具类提供的方法:
1 ThreadFactory threadFactory = Executors.defaultThreadFactory();
这也是 Executors 工具类提供的几种默认线程池所使用的 ThreadFactory。
缺点:只能使用默认属性,不提供任何定制参数,无法修改。
优点:实现了基本的线程名称自增。
3、使用 Guava 提供的 ThreadFactoryBuilder。优点是可以轻松定制四个线程属性,且支持线程名称自增:
1 2 3 4 5 6 ThreadFactory threadFactory = new ThreadFactoryBuilder () .setNameFormat("wechat-notify-%d" ) .setDaemon(false ) .setPriority(1 ) .setUncaughtExceptionHandler((thread, exception) -> {}) .build();
该实现如下,如果未提供自定义的 ThreadFactory,将基于 Executors.defaultThreadFactory() 进行二次修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private static ThreadFactory build (ThreadFactoryBuilder builder) { final String nameFormat = builder.nameFormat; final Boolean daemon = builder.daemon; final Integer priority = builder.priority; final UncaughtExceptionHandler uncaughtExceptionHandler = builder.uncaughtExceptionHandler; final ThreadFactory backingThreadFactory = (builder.backingThreadFactory != null ) ? builder.backingThreadFactory : Executors.defaultThreadFactory(); final AtomicLong count = (nameFormat != null ) ? new AtomicLong (0 ) : null ; return new ThreadFactory () { @Override public Thread newThread (Runnable runnable) { Thread thread = backingThreadFactory.newThread(runnable); if (nameFormat != null ) { thread.setName(format(nameFormat, count.getAndIncrement())); } if (daemon != null ) { thread.setDaemon(daemon); } if (priority != null ) { thread.setPriority(priority); } if (uncaughtExceptionHandler != null ) { thread.setUncaughtExceptionHandler(uncaughtExceptionHandler); } return thread; } }; }
阻塞队列 阻塞队列的使用详见另一篇《Java 集合框架系列(八)并发实现总结 》。
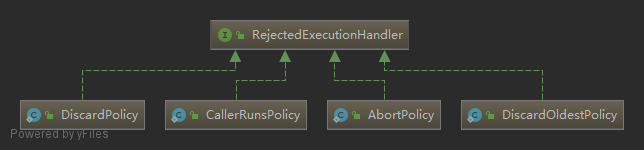
拒绝策略 拒绝策略,默认有四种实现:
AbortPolicy:抛出异常,默认的策略。DiscardPolicy:不处理,丢弃掉。DiscardOldestPolicy:丢弃队列中最近的一个任务,并执行该任务。CallerRunsPolicy:用调用者所在线程来执行该任务。
通过 RejectedExecutionHandler 接口可以实现更多策略,例如记录日志或持久化不能处理的任务,或者计数并发出告警。
1 2 3 public interface RejectedExecutionHandler { void rejectedExecution (Runnable r, ThreadPoolExecutor executor) ; }
⚠️ 注意:rejectedExecution 方法是在主线程中执行的。
构造方法 java.util.concurrent.ThreadPoolExecutor 提供了四个构造方法,以参数最多的为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0 ) throw new IllegalArgumentException (); if (workQueue == null || threadFactory == null || handler == null ) throw new NullPointerException (); this .acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this .corePoolSize = corePoolSize; this .maximumPoolSize = maximumPoolSize; this .workQueue = workQueue; this .keepAliveTime = unit.toNanos(keepAliveTime); this .threadFactory = threadFactory; this .handler = handler; }
钩子方法 java.util.concurrent.ThreadPoolExecutor 提供了三个钩子方法,参考 Hook methods :
This class provides protected overridable beforeExecute(Thread, Runnable)afterExecute(Runnable, Throwable)terminated()
钩子方法在源码中的调用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 final void runWorker (Worker w) { ... beforeExecute(wt, task); Throwable thrown = null ; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error (x); } finally { afterExecute(task, thrown); } ... }
例子:利用钩子方法清理 MDC 上下文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class MdcAwareThreadPoolExecutor extends ThreadPoolExecutor { public MdcAwareThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { super (corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler); } @Override protected void afterExecute (Runnable r, Throwable t) { System.out.println("Cleaning the MDC context" ); MDC.clear(); org.apache.log4j.MDC.clear(); ThreadContext.clearAll(); } }
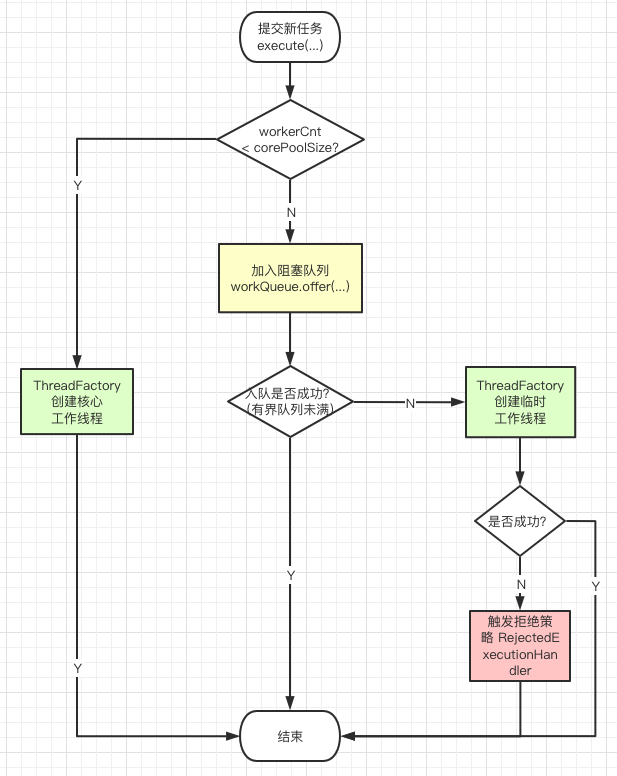
执行流程 execute 方法的整体执行流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */
统计指标 虽然我们用上了线程池,但是该如何了解线程池的运行情况,例如有多少线程在执行、多少在队列中等待?下表提供了方法:
Modifier and Type
Method and Description
备注
longgetTaskCount()任务总数(已完成任务数 + 当前活跃线程数)
longgetCompletedTaskCount()已完成任务数
intgetActiveCount()当前活跃中的工作线程数
intgetPoolSize()当前工作线程数
intgetLargestPoolSize()最大工作线程数
BlockingQueue<Runnable>getQueue()Access to the task queue is intended primarily for debugging and monitoring. 当前排队数
1 2 3 4 5 6 7 logger.info("{}, taskCount [{}], completedTaskCount [{}], activeCount [{}], queueSize [{}]" , threadPoolExecutor.getThreadNamePrefix(), threadPoolExecutor.getTaskCount(), threadPoolExecutor.getCompletedTaskCount(), threadPoolExecutor.getActiveCount(), threadPoolExecutor.getQueue().size() );
使用工厂类创建线程池 java.util.concurrent.ThreadPoolExecutor 提供了四个不同的构造方法,但由于它们的复杂性(参数较多),Java 并发 API 提供了 java.util.concurrent.Executors 工厂类来简化线程池的构造,常用方法如下:
1 2 3 4 5 6 7 8 public static ExecutorService newFixedThreadPool (...) {...}public static ExecutorService newSingleThreadExecutor (...) {...}public static ExecutorService newCachedThreadPool (...) {...}public static ScheduledExecutorService newScheduledThreadPool (...) {...}
但是这种方式并不推荐使用,参考《阿里巴巴 Java 开发手册》:
java.util.concurrent.Executors 源码分析如下,首先是 newFixedThreadPool(...) 和 newSingleThreadExecutor(...):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static ExecutorService newFixedThreadPool (int nThreads) { return new ThreadPoolExecutor (nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>()); } public static ExecutorService newSingleThreadExecutor () { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>())); }
上述方法中,关键在于对 java.util.concurrent.LinkedBlockingQueue 的构造,使用了默认的无参构造方法:
1 2 3 4 public LinkedBlockingQueue () { this (Integer.MAX_VALUE); }
然后是 newCachedThreadPool(...) 和 newScheduledThreadPool(...):
1 2 3 4 5 6 7 8 9 10 11 public static ExecutorService newCachedThreadPool () { return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue <Runnable>()); } public static ScheduledExecutorService newScheduledThreadPool (int corePoolSize) { return new ScheduledThreadPoolExecutor (corePoolSize); }
看下 java.util.concurrent.ScheduledThreadPoolExecutor 的构造方法:
1 2 3 4 5 public ScheduledThreadPoolExecutor (int corePoolSize) { super (corePoolSize, Integer.MAX_VALUE, 0 , NANOSECONDS, new DelayedWorkQueue ()); }
⚠️ 注意:ScheduledThreadPoolExecutor 使用的是 DelayedWorkQueue 队列,这个队列是无界的(无法设置 capacity),也就是说 maximumPoolSize 的设置其实是没有什么意义的。
corePoolSize 设置的太小,会导致并发任务量大时,延迟任务得不到及时处理,造成阻塞。corePoolSize 设置的太大,会导致并发任务量少时,造成大量的线程资源浪费。
参考 https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ThreadPoolExecutor.html
《如何合理估算 Java 线程池大小:综合指南 》
《如何合理地估算线程池大小? 》
《线程池执行的任务抛出异常会怎样? 》
《Java 线程池实现原理,及其在美团业务中的实践 》
《美团动态线程池实践思路及代码 》
《案例分析|线程池相关故障梳理&总结 | 阿里技术 》
《线程操纵术之更优雅的并行策略——Fork/Join | 阿里技术 》