Java 集合框架系列(七)Map 接口的使用场景总结
java.util.Map 用于映射键值对(map keys to values)。
本文总结了几种 Map 的使用场景,例如:
- 如何实现有序遍历;
- 如何实现缓存淘汰策略;
- 如何解决 Top K 问题。
- …
通用实现类
首先看看在 Java 中,默认为 Map 接口提供了哪些通用实现类:
HashMap(散列表实现)
参考:《Map 接口的散列表实现总结》
TreeMap(红黑树实现)
红黑树实现。
LinkedHashMap(散列表 + 双向链表实现)
LinkedHashMap 继承自 HashMap,是一种复合型数据结构。它在散列表的基础上,通过维护一个有界队列(双向链表实现)来实现「键值对」排序。
注意:
LinkedHashMap中的“Linked”实际上是指「链式队列」,而非指用链表法解决散列冲突。
这种行为适用于一些特定应用场景,例如:构建一个空间占用敏感的有限资源池,按某种淘汰策略自动淘汰「过期」元素:
| 排序方式 | 使用场景 |
|---|---|
按插入顺序(accessOrder = false) |
实现 FIFO 缓存淘汰策略 |
按访问顺序(accessOrder = true) |
实现 LRU 缓存淘汰策略 |
通过源码分析,LinkedHashMap 继承自 HashMap,同时 LinkedHashMap 的节点 Entry 也继承自 HashMap 的 Node,并且在此基础上增加了两个属性:
- 前驱节点
Entry<K, V> before - 后继节点
Entry<K, V> after
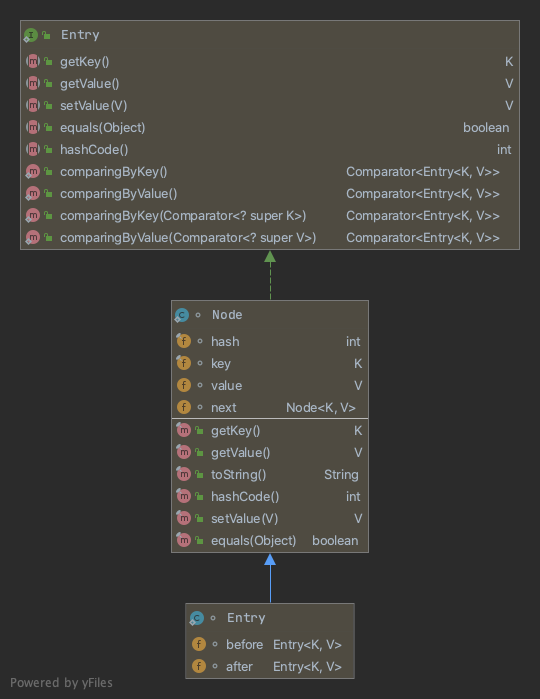
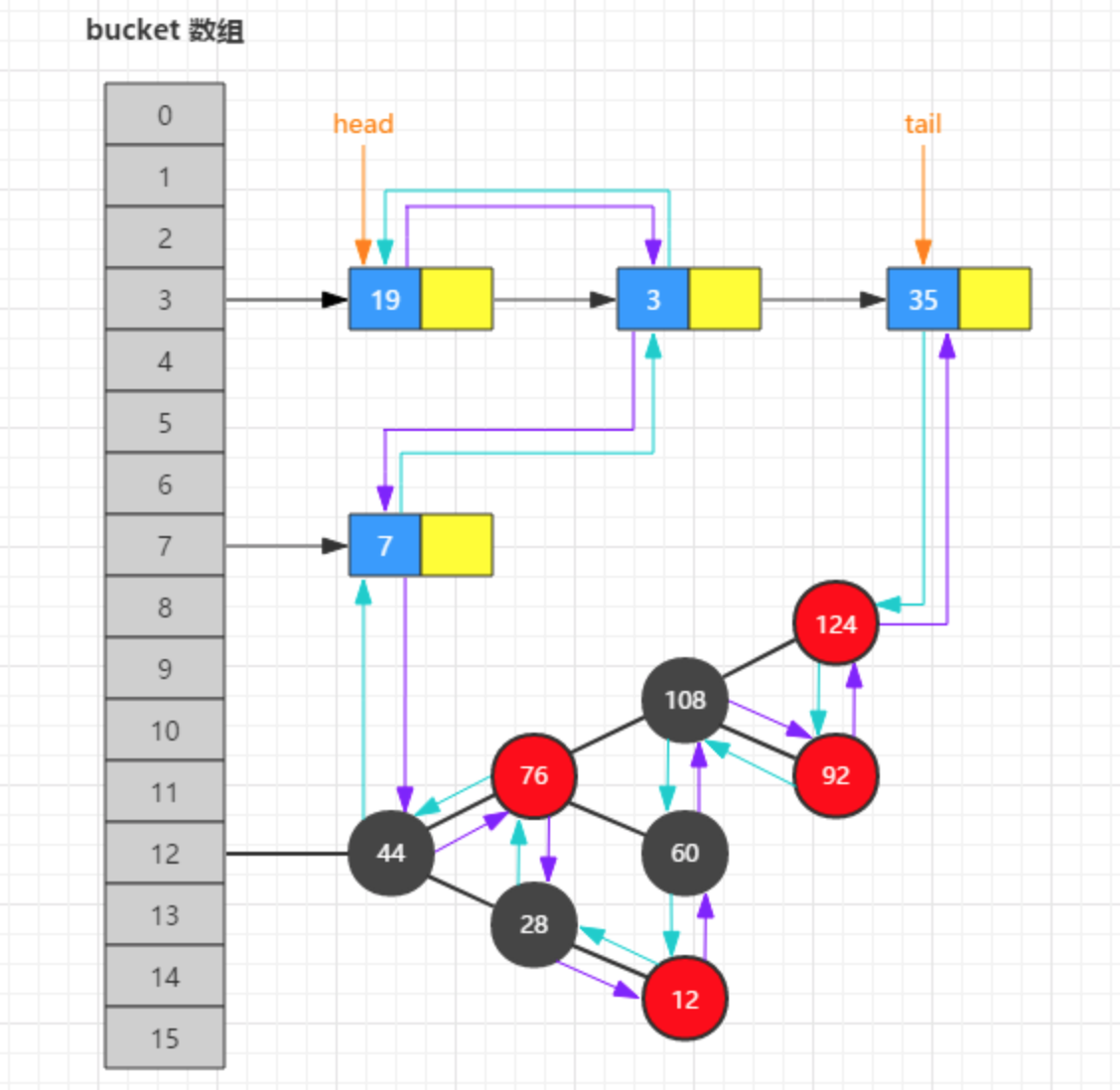
通过这两个属性就可以维护一条有序排列的双向链表,如下图:
创建 Map
使用 Guava 快速创建不可变的 Map:
1 | Map<String, String> map = ImmutableMap.of("A", "Apple", "B", "Boy", "C", "Cat"); |
使用 Guava 快速创建指定 initialCapacity 初始容量的 Map:
1 | Maps.newHashMapWithExpectedSize(10); |
Guava 的 Maps 还提供了更多的 API,可以自行研究使用。
实现有序遍历
集合视图
Map 接口提供了三种集合视图(collection views):
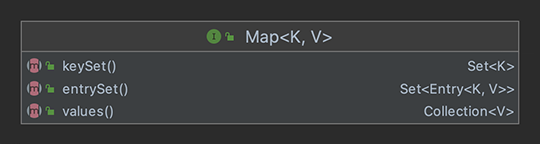
注意:从
keySet()返回类型可知,由于受限于Set的三大特性之一「互异性」,Map不能包含重复的键(Key)。两个键重复与否取决于equals与hashCode()方法。
Many methods in Collections Framework interfaces are defined in terms of the
equalsmethod. For example, the specification for thecontainsKey(Object key)method says: “returnstrueif and only if this map contains a mapping for a keyksuch that(key==null ? k==null : key.equals(k)).” This specification should not be construed to imply that invokingMap.containsKeywith a non-null argumentkeywill causekey.equals(k)to be invoked for any keyk. Implementations are free to implement optimizations whereby theequalsinvocation is avoided, for example, by first comparing the hash codes of the two keys. (TheObject.hashCode()specification guarantees that two objects with unequal hash codes cannot be equal.) More generally, implementations of the various Collections Framework interfaces are free to take advantage of the specified behavior of underlyingObjectmethods wherever the implementor deems it appropriate.
hashCode 需要遵循以下规则:

遍历 API
Java 提供了下面几种 API 用于遍历 Map 接口的三种集合视图(collection views):
The order of a map is defined as the order in which the iterators on the map’s collection views return their elements. Some map implementations, like the
TreeMapclass, make specific guarantees as to their order; others, like theHashMapclass, do not.
内部循环 API
1 | // key 遍历 |
外部循环 API
1 | // key 遍历 |
1 | // entry 显式迭代器 |

遍历顺序
遍历顺序取决于 Map 接口使用了何种数据结构实现。
众所周知,散列表这种动态数据结构虽然支持非常高效的数据插入、删除、查找操作(平均时间复杂度都为常数阶 O(1)),但由于散列表中的数据都是通过散列函数运算之后无序存储的,因此散列表的遍历结果也是无序的,例如 HashMap。
要实现某种有序遍历的解决方案:
排序算法。每当我们希望按照某种顺序遍历散列表中的数据时,自行将散列表中的数据拷贝到数组中,然后通过某种排序算法完成排序,再进行遍历。但如此一来,效率势必会很低。
换一种数据结构实现,例如:红黑树(
TreeMap)。设计一种复合型数据结构,例如将散列表与链式队列结合在一起(
LinkedHashMap),实现某种排序,从而达到有序遍历。
无序(no order)
1 | /** |
按自然顺序(natual order)
1 | /** |
排序由键(Key)的自然顺序决定,通过 Comparator 或 Comparable。
按插入顺序(insertion order)
1 | /** |
按访问顺序(access order)
1 | /** |
实现缓存淘汰策略
FIFO (First In First Out)
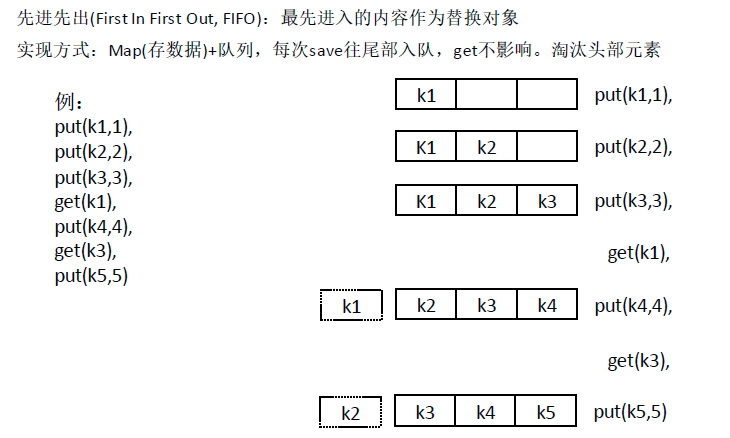
1 | /** |
LRU (Least Recently Used)
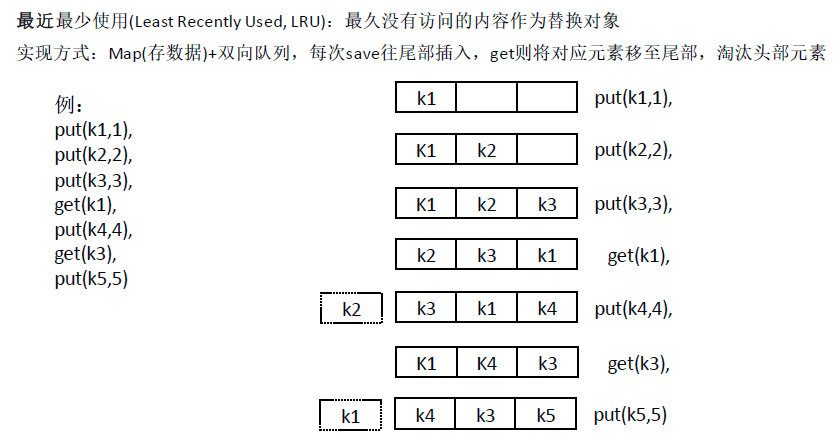
1 | /** |
LFU (Least Frequently Used)
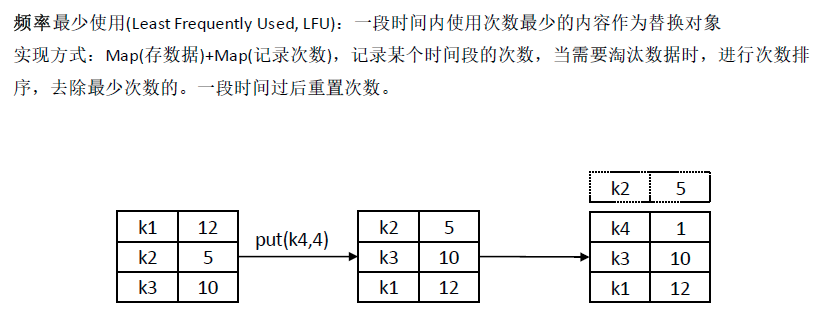
实现合并
| Modifier and Type | Method and Description |
|---|---|
default V |
merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)If the specified key is not already associated with a value or is associated with null, associates it with the given non-null value. |
实现计数器
Java 8 为 Map 接口引入了一组新的 default 默认方法,用于简化 Map 的日常使用。API 如下:
| Modifier and Type | Method and Description |
|---|---|
default V |
putIfAbsent(K key, V value)If the specified key is not already associated with a value (or is mapped to null) associates it with the given value and returns null, else returns the current value. |
default V |
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)If the specified key is not already associated with a value (or is mapped to null), attempts to compute its value using the given mapping function and enters it into this map unless null. |
default V |
computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)If the value for the specified key is present and non-null, attempts to compute a new mapping given the key and its current mapped value. |
default V |
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)Attempts to compute a mapping for the specified key and its current mapped value (or null if there is no current mapping). |
要实现类似 Redis 散列表的原子递增命令 HINCRBY key field increment 的效果,使用 compute 实现的代码,对比传统代码更紧凑:
1 | private static final Map<String, Integer> IP_STATS = new HashMap<>(); |
最终结果:
1 | // result is 1 |
解决 Top K 问题
解题思路:
- 数据规模大的,就先分而治之(hash 映射);
- 数据规模小的:
- 首先,按「键值对」保存统计数据(key 为关键字,value 为统计次数)
- 然后,按「值」倒序
- 最后,取 Top K 个「键」
1 | /** |
输出结果:
1 | Before sort: |
解码 Huffman coding
参考维基百科 Huffman coding 的定义:
In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression.
前缀编码(prefix code) 的定义:
如果在一个编码方案中,任何一个编码都不是其它任何编码的前缀(最左子串),则称该编码是前缀编码。前缀编码可以保证对压缩数据进行解码时不产生二义性,确保正确解码。
前缀编码有两种编码方案:
- 等长编码方案(fixed-length coding)
- 不等长编码方案(variable-length coding)
Huffman coding 是一种最优前缀编码,属于不等长编码方案。
参考:https://www.csdn.net/tags/MtTaMgysMjE3NjItYmxvZwO0O0OO0O0O.html
题目:已知字符对应的前缀编码表,给定一串编码,将其解码为字符串。
解答:https://blog.csdn.net/qq_45273552/article/details/109176832
参考
https://docs.oracle.com/javase/8/docs/api/java/util/Map.html