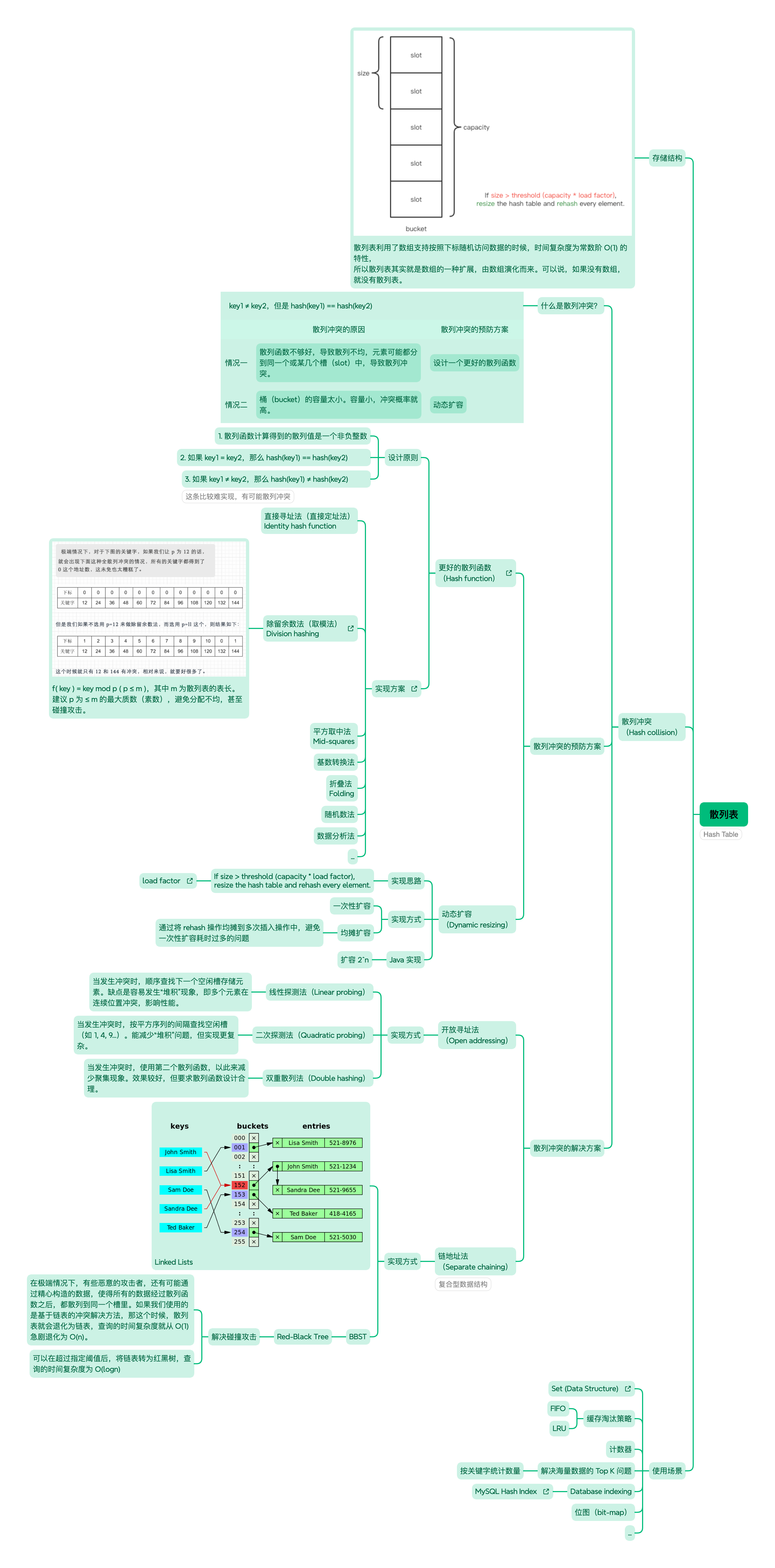
/** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */ staticclassNode<K,V> implementsMap.Entry<K,V> { finalint hash; final K key; V value; Node<K,V> next;
publicfinal K getKey() { return key; } publicfinal V getValue() { return value; } publicfinal V setValue(V newValue) { VoldValue= value; value = newValue; return oldValue; }
publicfinalbooleanequals(Object o) { if (o == this) returntrue; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) returntrue; } returnfalse; }
/** * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node. */ staticfinalclassTreeNode<K,V> extendsLinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); }
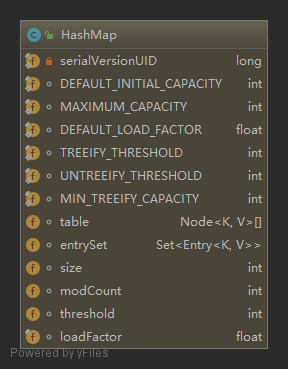
/** * The default initial capacity - MUST be a power of two. * 数组默认初始容量为 16,必须是 2 的 n 次幂 */ staticfinalintDEFAULT_INITIAL_CAPACITY=1 << 4; // aka 16
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. * * 数组最大容量,,必须是 2 的 n 次幂,且小于等于 2^30 */ staticfinalintMAXIMUM_CAPACITY=1 << 30;
/** * The load factor used when none specified in constructor. * 默认装载因子 */ staticfinalfloatDEFAULT_LOAD_FACTOR=0.75f;
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. * * 桶树化时的阈值 */ staticfinalintTREEIFY_THRESHOLD=8;
/** * The bin count threshold for untreeifying a (split) bin during a * resize operation. Should be less than TREEIFY_THRESHOLD, and at * most 6 to mesh with shrinkage detection under removal. * * 桶非树化时的阈值 */ staticfinalintUNTREEIFY_THRESHOLD=6;
/** * The smallest table capacity for which bins may be treeified. * (Otherwise the table is resized if too many nodes in a bin.) * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts * between resizing and treeification thresholds. * * 树化时数组最小容量 */ staticfinalintMIN_TREEIFY_CAPACITY=64;
/** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) * * 底层数组 */ transient Node<K,V>[] table;
/** * Holds cached entrySet(). Note that AbstractMap fields are used * for keySet() and values(). */ transient Set<Map.Entry<K,V>> entrySet;
/** * The number of key-value mappings contained in this map. * * 实际存储的键值对数量 */ transientint size;
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). * * 修改次数 */ transientint modCount;
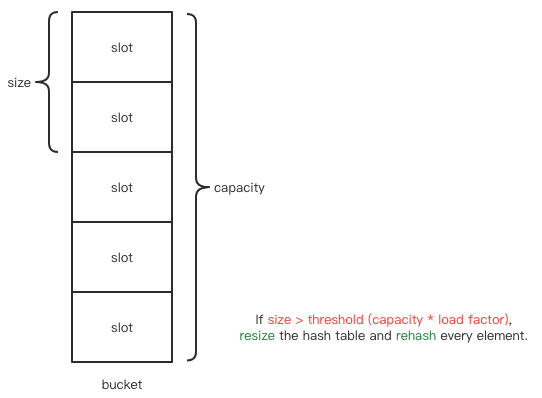
/** * The next size value at which to resize (capacity * load factor). * * resize 操作的阈值(capacity * load factor) */ int threshold;
/** * The load factor for the hash table. * * 装载因子 */ finalfloat loadFactor;
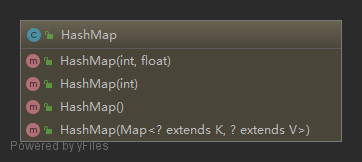
/** * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and load factor. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ publicHashMap(int initialCapacity, float loadFactor) { // 参数校验及默认值设置 if (initialCapacity < 0) thrownewIllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) thrownewIllegalArgumentException("Illegal load factor: " + loadFactor); // 装载因子及扩容阈值赋值 this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }
/** * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and the default load factor (0.75). * * @param initialCapacity the initial capacity. * @throws IllegalArgumentException if the initial capacity is negative. */ publicHashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }
/** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ publicHashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
/** * Constructs a new <tt>HashMap</tt> with the same mappings as the * specified <tt>Map</tt>. The <tt>HashMap</tt> is created with * default load factor (0.75) and an initial capacity sufficient to * hold the mappings in the specified <tt>Map</tt>. * * @param m the map whose mappings are to be placed in this map * @throws NullPointerException if the specified map is null */ publicHashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
/** * Creates a {@code HashMap} instance, with a high enough "initial capacity" * that it <i>should</i> hold {@code expectedSize} elements without growth. * This behavior cannot be broadly guaranteed, but it is observed to be true * for OpenJDK 1.7. It also can't be guaranteed that the method isn't * inadvertently <i>oversizing</i> the returned map. * * @param expectedSize the number of entries you expect to add to the * returned map * @return a new, empty {@code HashMap} with enough capacity to hold {@code * expectedSize} entries without resizing * @throws IllegalArgumentException if {@code expectedSize} is negative */ publicstatic <K, V> HashMap<K, V> newHashMapWithExpectedSize(int expectedSize) { returnnewHashMap<K, V>(capacity(expectedSize)); }
/** * Returns a capacity that is sufficient to keep the map from being resized as * long as it grows no larger than expectedSize and the load factor is >= its * default (0.75). */ staticintcapacity(int expectedSize) { if (expectedSize < 3) { checkNonnegative(expectedSize, "expectedSize"); return expectedSize + 1; } if (expectedSize < Ints.MAX_POWER_OF_TWO) { // This is the calculation used in JDK8 to resize when a putAll // happens; it seems to be the most conservative calculation we // can make. 0.75 is the default load factor. return (int) ((float) expectedSize / 0.75F + 1.0F); } return Integer.MAX_VALUE; // any large value }
/** * Returns a power of two size for the given target capacity. */ staticfinalinttableSizeFor(int cap) { intn= cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
/** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ staticfinalinthash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
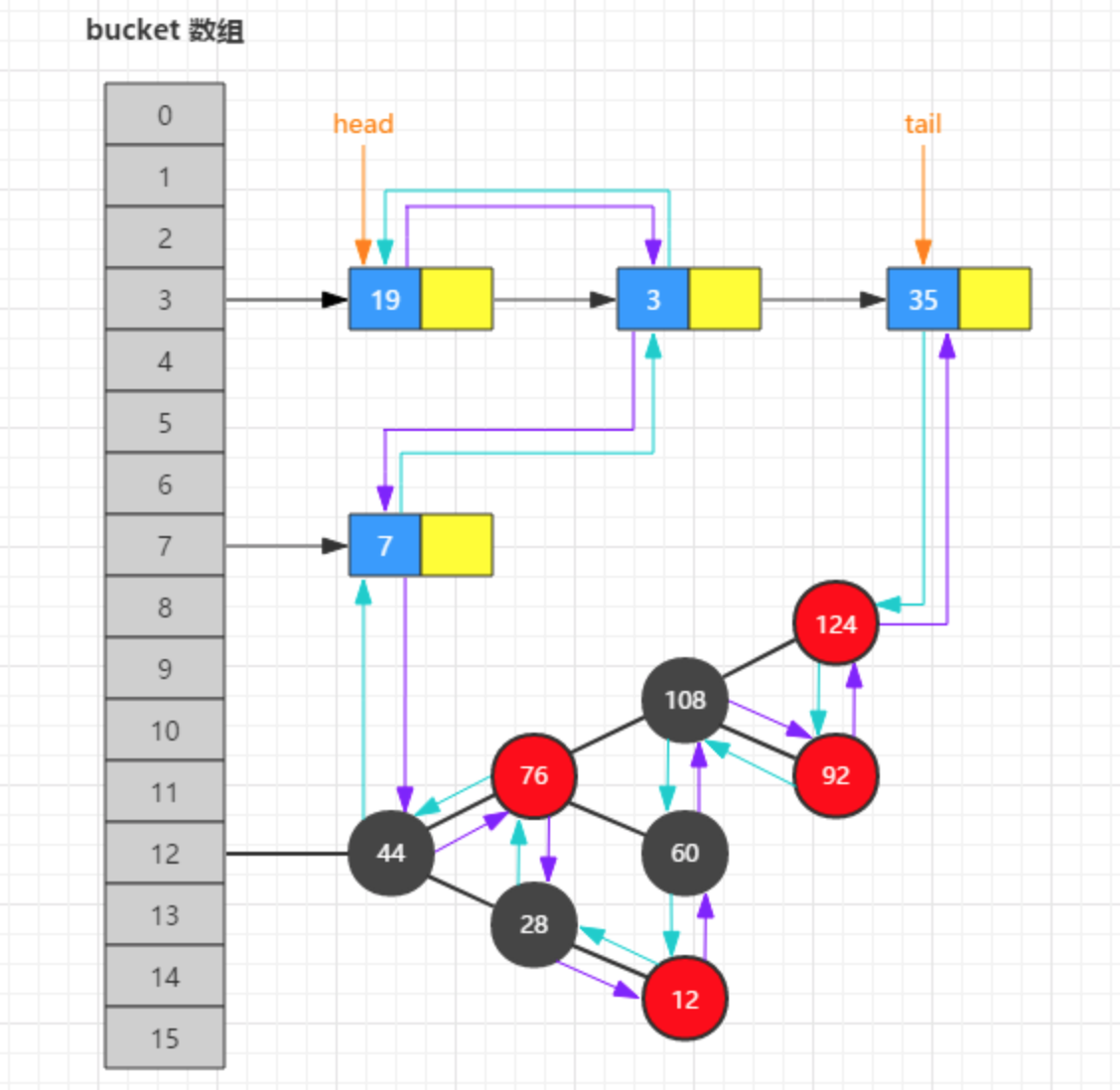
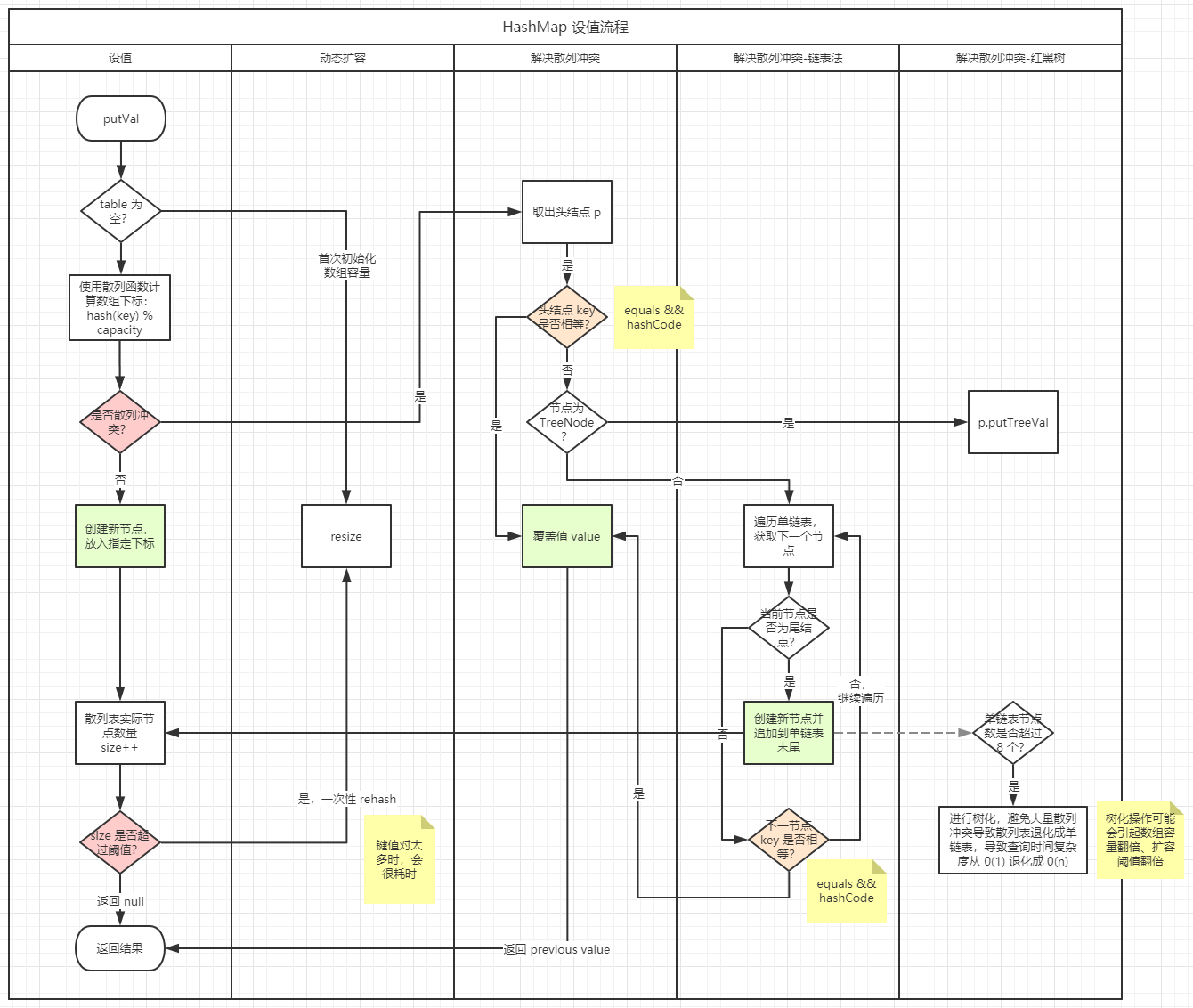
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // tab 表示底层数组 // p 表示头结点 // n 表示数组长度 // i 表示数组下标 Node<K,V>[] tab; Node<K,V> p; int n, i; // 节点数组为空,则首次初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
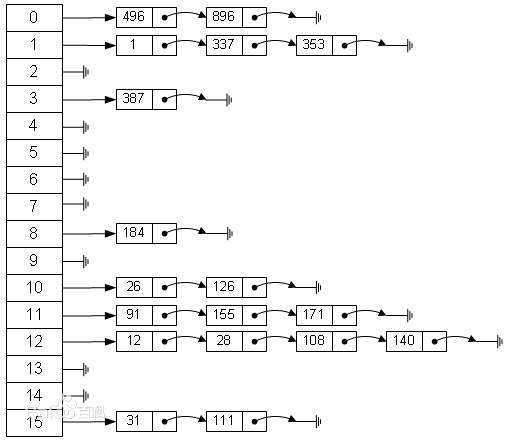
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. */ finalvoidtreeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); elseif ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }
/** * Implements Map.remove and related methods * * @param hash hash for key * @param key the key * @param value the value to match if matchValue, else ignored * @param matchValue if true only remove if value is equal * @param movable if false do not move other nodes while removing * @return the node, or null if none */ final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; elseif ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); elseif (node == p) tab[index] = node.next; else p.next = node.next;
++modCount; --size; afterNodeRemoval(node);
return node; } } returnnull; }
resize
用于初始化或扩容散列表。
1 2 3 4 5 6 7 8 9 10 11 12
/** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target held in field threshold. * Otherwise, because we are using power-of-two expansion, the * elements from each bin must either stay at same index, or move * with a power of two offset in the new table. * * @return the table */ final Node<K,V>[] resize() { ... }
@Override public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
@Override public V putIfAbsent(K key, V value) { return putVal(hash(key), key, value, true, true); }
/** * Copies all of the mappings from the specified map to this map. * These mappings will replace any mappings that this map had for * any of the keys currently in the specified map. * * @param m mappings to be stored in this map * @throws NullPointerException if the specified map is null */ @Override publicvoidputAll(Map<? extends K, ? extends V> m) { putMapEntries(m, true); }
/** * Implements Map.putAll and Map constructor * * @param m the map * @param evict false when initially constructing this map, else * true (relayed to method afterNodeInsertion). */ finalvoidputMapEntries(Map<? extends K, ? extends V> m, boolean evict) { ints= m.size(); if (s > 0) { if (table == null) { // pre-size floatft= ((float)s / loadFactor) + 1.0F; intt= ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY); if (t > threshold) threshold = tableSizeFor(t); } elseif (s > threshold) resize(); for (Map.Entry<? extendsK, ? extendsV> e : m.entrySet()) { Kkey= e.getKey(); Vvalue= e.getValue(); putVal(hash(key), key, value, false, evict); } } }