GNU 常用文本处理命令
续上文。
GNU/CoreUtils 的 Text utilities 提供了一些便利的文本处理命令,配合“管道”组合使用可以大大提高文本处理效率。
命令
下面介绍一些最常用的利用管道进行组合的命令:
grep
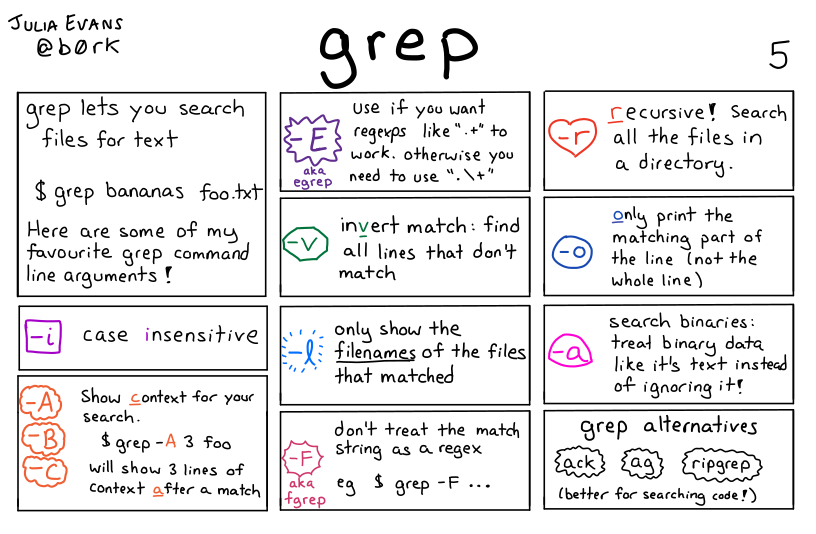
grep 命令使用正则表达式以行为单位进行文本搜索(global search regular expression(RE) and print out the line),其命令格式如下:
1 | grep [选项] 'PATTERN' [文本文件] |
常用选项:
| 选项 | 描述 | 例子 |
|---|---|---|
-c, --count |
打印匹配的行数 | |
-m NUM, --max-count=NUM |
打印前 NUM 行 | |
-n, --line-number |
打印行号 | |
-v, --revert-match |
反转查找(非) | |
-A , --after |
可加数字,表示打印后面n行 | |
-B , --before |
可加数字,表示打印前面n行 | |
-i |
不区分大小写 | |
-r |
递归目录查找 | grep -r "XXX" * |
--color |
关键字高亮 | |
-E |
使用正则表达式,替代 egrep 命令 |
|
-F |
在一个或多个文件中搜索固定的字符串,替代 fgrep 命令 |
且(AND):
1 | # 使用管道符连接多个 grep 命令 |
或(OR):
1 | # 方法一:使用转义字符 \| |
非(NOT):
1 | grep -v 'pattern' filename |
参考:
https://stackoverflow.com/questions/9969414/always-include-first-line-in-grep
tr
tr 命令用于替换或删除指定的字符(注意不接收文件参数),其命令格式如下:
1 | tr [options] string1 string2 |
可用于将小写转换成大写:
1 | $ echo 'abcdef' | tr 'a-z' 'A-Z' |
-d 参数可用于删除指定的字符:
1 | $ echo 'abcdef' | tr -d 'def' |
-s 参数可用于删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串:
1 | $ echo 'abbbbbbbbbc' | tr -s 'b' |
-d 和 -s 常用于删除所有换行符 \n 和合并空格 [:space:]:
1 | $ cat logfile | tr -d '\n\t' | tr -s [:space:] |
cut
cut 命令以行为单位,用于截取某段数据,如字节、字符和字段。其命令格式如下:
1 | cut [选项] [范围] [文本文件] |
使用 -d 指定分隔符(默认为制表符),例如:cut -d ':' -f -2 /etc/passwd。
常用的几种选项如下:
| 选项 | 描述 |
|---|---|
-f, --fields |
以字段为单位 |
-c, --characters |
以字符为单位 |
-b, -- bytes |
以字节为单位 |
常用的几种范围如下:
| 选项 | 描述 |
|---|---|
n |
第 n 个 |
n- |
从第 n 个到最后一个 |
n-m |
从第 n 个到第 m 个 |
-m |
从第一个到第 m 个 |
- |
从第一个到最后一个 |
n,m |
第 n、m 个 |
注意,在 UTF-8 编码下,汉字占三个字节。
sort
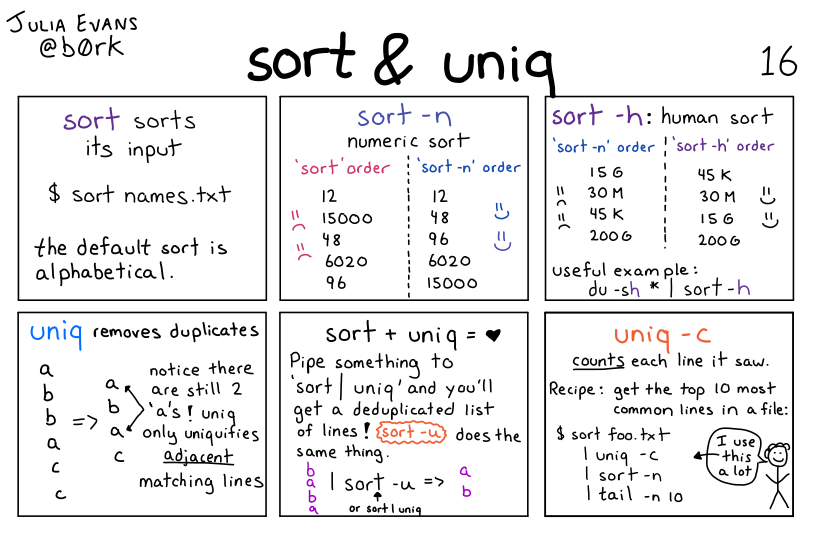
sort 命令以行为单位,用于对文本文件内容进行排序。其命令格式如下:
1 | sort [选项] [文本文件] |
常用的选项如下:
| 选项 | 描述 |
|---|---|
-n, --numeric-sort, --sort=numeric |
依照数值的大小排序(默认是以文字) |
-r, --reverse |
反向排序 |
uniq
uniq 命令以行为单位,用于合并文本文件中重复出现的行列。它比较相邻的行,在正常情况下,第二个及以后更多个重复行将被删去,因此在合并前常常会先使用 sort 命令排序。行比较是根据所用字符集的排序序列进行的。其命令格式如下:
1 | uniq [选项] [文本文件] |
常用的选项如下:
| 选项 | 描述 |
|---|---|
-i, --ignore-case |
Case insensitive comparison of lines. 忽略大小写 |
-c, --count |
Precede each output line with the count of the number of times the line occurred in the input, followed by a single space. 进行计数 |
-d, --repeated |
Output a single copy of each line that is repeated in the input. 只显示重复行(交集) |
-u, --unique |
Only output lines that are not repeated in the input. 只显示不重复的行(差集) |
例子:
1 | cat a b | sort | uniq > c # c is a union b |
wc
wc 命令用于统计字节数、字数、行数,其命令格式如下:
1 | wc [选项] [文本文件] |
常用的选项如下:
| 选项 | 描述 |
|---|---|
-l, --lines |
只显示行数 |
-w, --words |
只显示字数 |
-c, --chars 或 --bytes |
只显示字节数 |
tee
tee 是一种双向重定向命令,用于可以将数据流处理过程中的某段结果保存到文件,其处理过程如下:
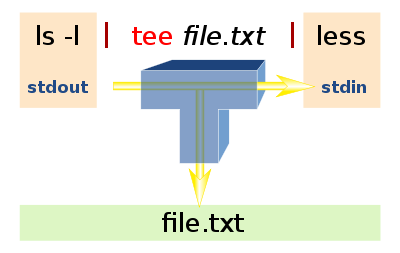
常用的选项如下:
| 选项 | 描述 |
|---|---|
-a, --append |
附加到既有文件的后面,而非覆盖它 |
-i, --ignore-interrupts |
忽略中断信号 |
xargs

例子
1、统计 Nginx 独立 IP 数:
1 | $ cut -d " " -f 1 nginx_log | sort | uniq | wc –l |
2、统计当前用户最常用的 10 条命令:
1 | $ cut -d " " -f 1 ~/.bash_history | sort | uniq -c | sort -nr | head |
3、统计重复行,逆序方式:
1 | $ sort /data/tradehistory_20150804.txt | uniq -cd | sort -nr |
4、统计多个文件:
1 | $ cat /data/tradehistory_2015080*.txt | cut -d ',' -f 13 | sort | uniq -c | sort -nr |