分布式 ID 之雪花算法实现
雪花算法介绍
雪花算法(Snowflake)是 Twitter 提出来的一个算法,其目的是生成一个 64 bit 的二进制数:

转换为十进制和十六进制分别如下图。其中十进制的最大长度为 19 位:
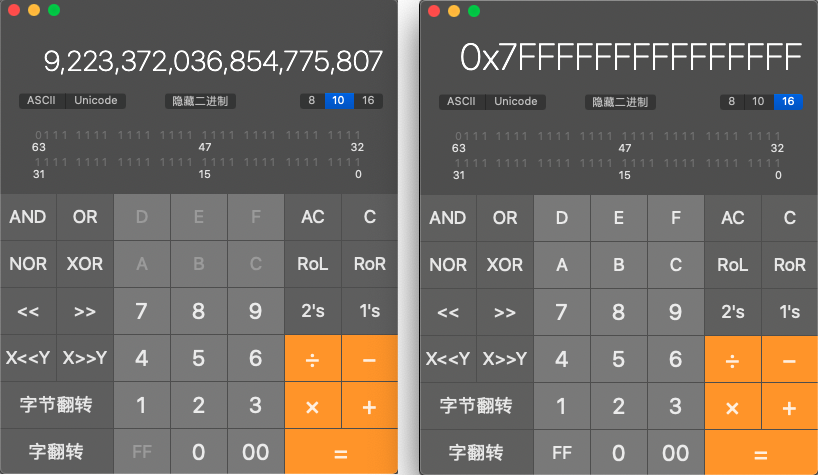
该二进制数分解如下:
42 bit:用来记录时间戳,表示自 1970-01-01T00:00:00Z 之后经过的毫秒数(millisecond),其中 1 bit 是符号位。由于精确到毫秒(millisecond),相比有符号 32 bit 所存储的精度为秒(second)的时间戳需要多 10 bit 来记录毫秒数(0-999)。42 bit 可以记录 69 年,如果设置好起始时间例如 2018 年,那么可以用到 2087 年。42 bit 时间戳范围如下:
1
2
3
4
5
6
7
8
9
10
11
12
13// 0
long a = 0b00_00000000_00000000_00000000_00000000_00000000L;
// 999
long b = 0b00_00000000_00000000_00000000_00000011_11100111L;
// 2^41-1, 2199023255551
long c = 0b01_11111111_11111111_11111111_11111111_11111111L;
// 1970-01-01T00:00:00.000Z
Instant.ofEpochMilli(a).atZone(ZoneOffset.of("-00:00")).toLocalDateTime();
// 1970-01-01T00:00:00.999Z
Instant.ofEpochMilli(b).atZone(ZoneOffset.of("-00:00")).toLocalDateTime();
// 2039-09-07T15:47:35.551Z
Instant.ofEpochMilli(c).atZone(ZoneOffset.of("-00:00")).toLocalDateTime();10 bit:用来记录机器 ID,最多可以记录 2^10-1=1023 台机器,一般用前 5 位代表数据中心,后面 5 位是某个数据中心的机器 ID

12 bit:循环位,用来对同一个毫秒之内产生的 ID,12 位最多可以记录 2^12-1=4095 个,也就是在同一个机器同一毫秒最多记录 4095 个,多余的需要进行等待下个毫秒。

上面只是一个将 64 bit 划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
- 服务目前 QPS10 万,预计几年之内会发展到百万。
- 当前机器三地部署,上海,北京,深圳都有。
- 当前机器 10 台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分 64 bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求(100 W / 1000 ms / 10 台)。为了保证扩展,后面的循环位可以限制到 1024,也就是 2^10,那么循环位 10 位就足够了。
机器三地部署我们可以用 3 bit 总共 8 来表示机房位置;当前机器 10 台,为了保证能够扩展到百台那么可以用 7 bit 总共 128 来表示;时间位依然是 42 bit。那么还剩下 64-10-3-7-42 = 2 bit,剩下 2 bit 可以用来进行扩展。
雪花算法实现
下面是我的对雪花算法的实现,涉及几点思考:
- 为了节省空间、提升运算性能,主要使用到位运算,而不是字符串操作。
- 为了提高可配置性,将每一部分的位数抽取成了常量,以便自定义。
- 解决时间回拨问题:
- 如果回拨时长较短(可配置,代码中配了 5 ms),线程等待并重试即可;
- 如果回拨时长较长,则利用扩展位避免生成重复 ID(扩展位可配,代码中配置了 3 位,即最多支持 3 次回拨,超出则抛异常)。
1 | import lombok.SneakyThrows; |
输出结果:
1 | Binary is 110000011011010011001111001101001100000111000011000000000100000, id is 6979004485312020512 |
位运算过程如下:
timestamp = id >> TIMESTAMP_SHIFT1
201100000 11011010 01100111 10011010 01100000 11100001 10000000 00100000
>> 01100000 11011010 01100111 10011010 01100000 11dataCenterNo = id >> DATA_CENTER_NO_SHIFT & MAX_DATA_CENTER_NO1
2
3
401100000 11011010 01100111 10011010 01100000 11100001 10000000 00100000
>> 01100000 11011010 01100111 10011010 01100000 1110
& 11
= 10workerNo = id >> WORKER_NO_SHIFT & MAX_WORKER_NO1
2
3
401100000 11011010 01100111 10011010 01100000 11100001 10000000 00100000
>> 01100000 11011010 01100111 10011010 01100000 11100001 1
& 1111 1
= 1 1seqNo = id >> SEQ_NO_SHIFT & MAX_SEQ_NO1
2
3
401100000 11011010 01100111 10011010 01100000 11100001 10000000 00100000
>> 01100000 11011010 01100111 10011010 01100000 11100001 10000000 00100
& 1111111 11111
= 100ext = id & MAX_EXT1
2
301100000 11011010 01100111 10011010 01100000 11100001 10000000 00100000
& 111
= 0
延伸阅读
位运算
位运算符如下:
1 | &:按位与 |
例如,Java 中求 key 应当放到散列表的哪个位置(offset):
1 | static final int getOffset(Object key, int length) |
参考:
- 《Java 位运算符 &、|、^、~、<<、>>、>>>》
- 《按位异或的用途》
- 《按位与的用途:子网划分(IP 地址与子网掩码做与运算求子网地址)》
UNIX 时间戳
参考:UNIX 时间戳总结