并发编程系列(二)Java 并发包总结
工作中常用到一些并发编程类,这里做一些总结。
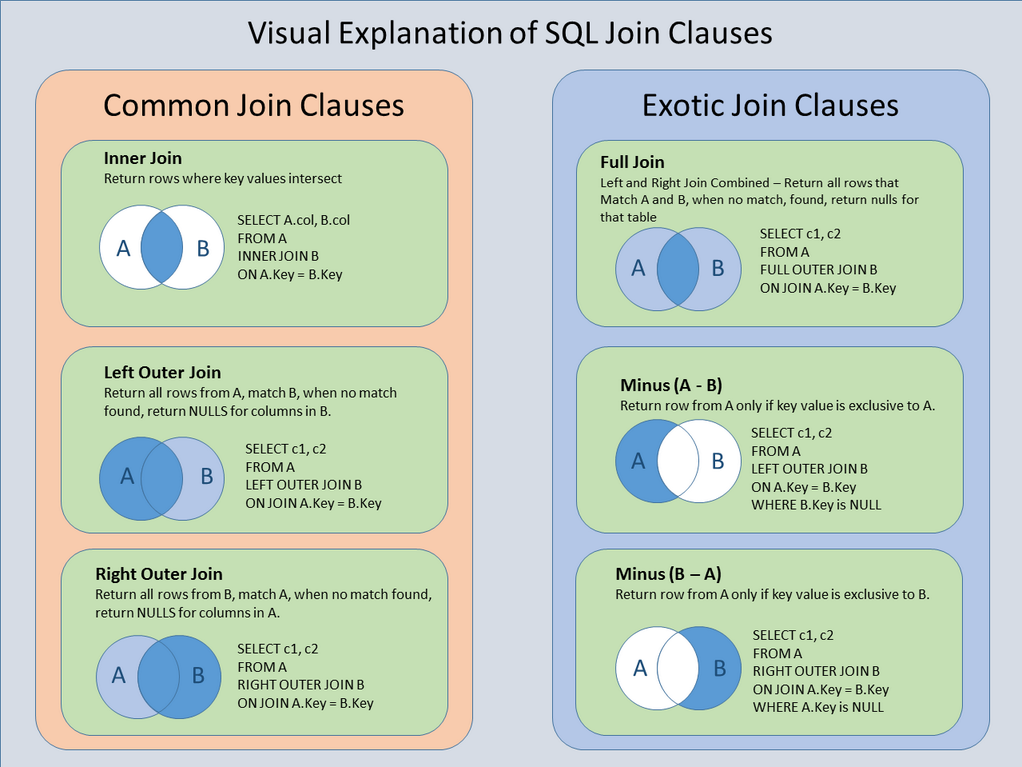
JDK 中涉及到线程的包如下:
java.lang
内含基础并发类。
Runnable
无返回结果的异步任务。
Thread
程序中的执行线程。
属性
Thread 对象中保存了一些属性能够帮助我们来辨别每一个线程,知道它的状态,调整控制其优先级等:
ID
每个线程的独特标识。
Name
线程的名称。
Priority
线程对象的优先级。优先级别在 1-10 之间,1 是最低级,10 是最高级。不建议改变它们的优先级。
Daemon
是否为守护线程。
Java 有一种特别的线程叫做守护线程。这种线程的优先级非常低,通常在程序里没有其他线程运行时才会执行它。当守护线程是程序里唯一在运行的线程时,JVM 会结束守护线程并终止程序。
根据这些特点,守护线程通常用于在同一程序里给普通线程(也叫使用者线程)提供服务。它们通常无限循环的等待服务请求或执行线程任务。它们不能做重要的任务,因为我们不知道什么时候会被分配到 CPU 时间片,并且只要没有其他线程在运行,它们可能随时被终止。JAVA中最典型的这种类型代表就是垃圾回收器 GC。
只能在 start() 方法之前可以调用 setDaemon() 方法。一旦线程运行了,就不能修改守护状态。
可以使用 isDaemon() 方法来检查线程是否是守护线程。
Thread.UncaughtExceptionHandler
用于捕获和处理线程对象抛出的 Unchecked Exception 来避免程序终结。
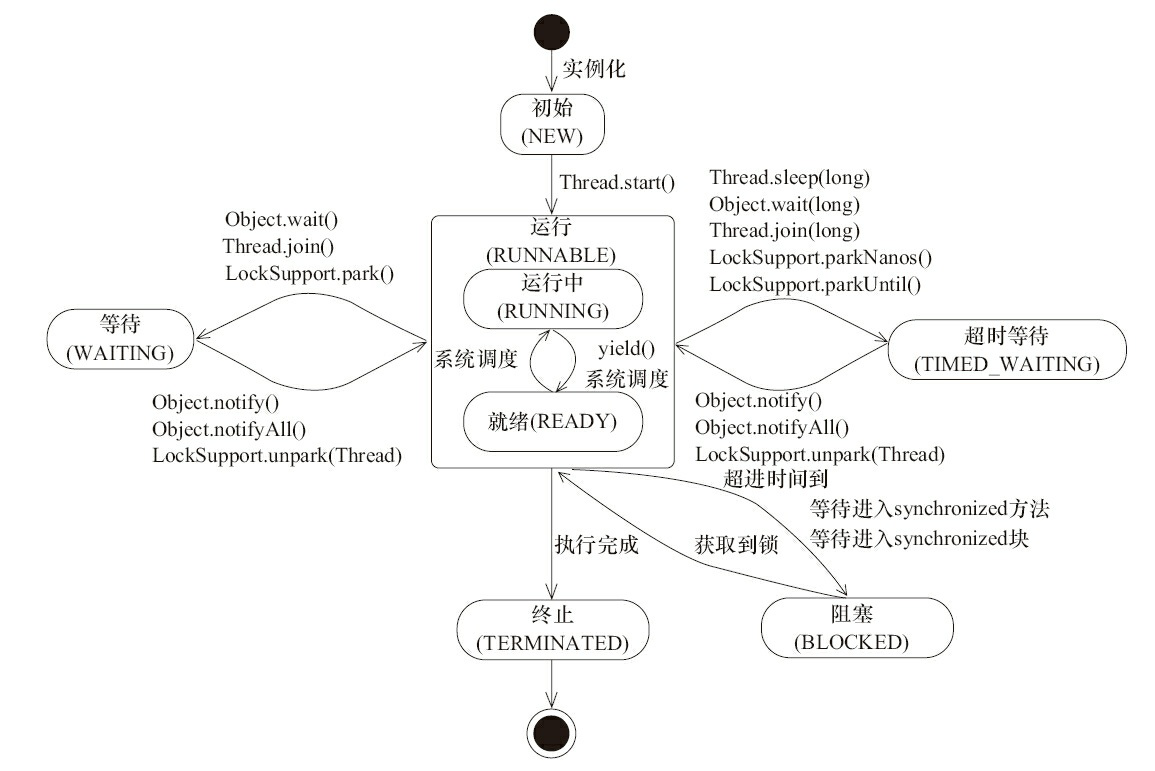
Thread.State
线程的状态,共六种:
NEW
RUNNABLE
BLOCKED
WAITING
TIME_WAITING
TERMINATED
方法
Thread 类提供了以下几类方法:
- 线程睡眠
Thread.sleep(...) - 线程中断
Thread.interrupt() - 线程让步
Thread.yield() - 线程合并
Thread.join(...) - ……
Object 提供了一组线程协作方法:
- 线程协作
Object.wait/notify
ThreadLocal<T>
ThreadLocal 存放的值是线程内共享的,线程间互斥的,主要用于在线程内共享一些数据。
try-with-resources
可以通过实现 AutoCloseable 以使用 try-with-resources 语法简化 ThreadLocal 资源清理:
1 | try (ChannelContext ctx = new ChannelContext(channel)) { |
实现如下:
1 |
|
父子线程的值传递
https://docs.oracle.com/javase/8/docs/api/java/lang/InheritableThreadLocal.html
异步执行的上下文传递
https://github.com/alibaba/transmittable-thread-local
java.util.concurrent
JDK 5 引入的 Executor Framework ,用于取代传统的并发编程。

Callable
有返回结果的异步任务。
Executor Framework 的一个重要优点是提供了 java.util.concurrent.Callable<V> 接口用于返回异步任务的结果。它的用法跟 Runnable 接口很相似,但它提供了两种改进:
Callable接口中主要的方法叫call(),可以返回结果。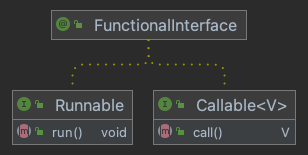
当你将
Callable对象submit到Executor执行者,你可以获取一个实现Future对象,你可以用这个对象来控制和获取Callable对象的状态和结果。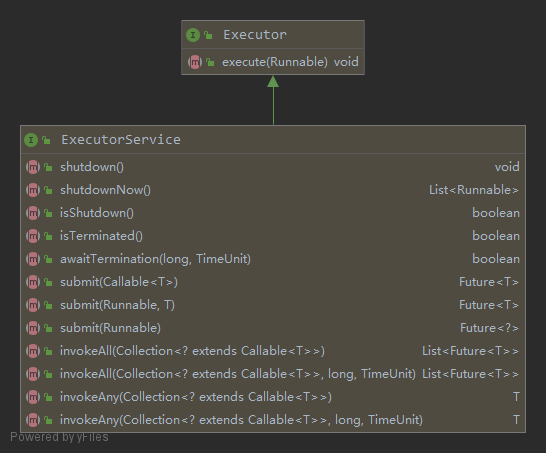
工具类
CountDownLatch
CyclicBarrier
Phaser
CompletableFuture
Semaphore
Exchanger
Executors
线程池
参考另一篇《并发编程系列(三)Java 线程池总结》。
并发集合
详见另一个篇《Java 集合框架系列(九)并发实现总结》。
显式锁
java.util.concurrent.locks
用于实现线程安全与通信。
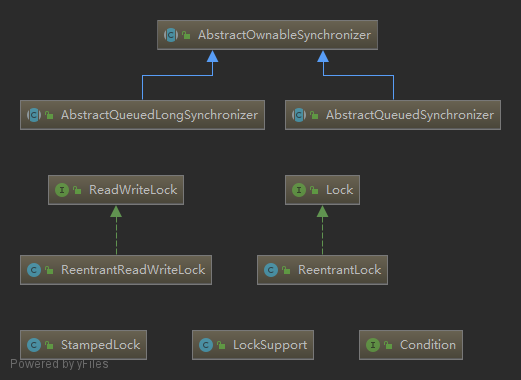
原子类
java.util.concurrent.atomic
使用这些数据结构可以避免在并发程序中使用同步代码块(synchronized 或 Lock)。
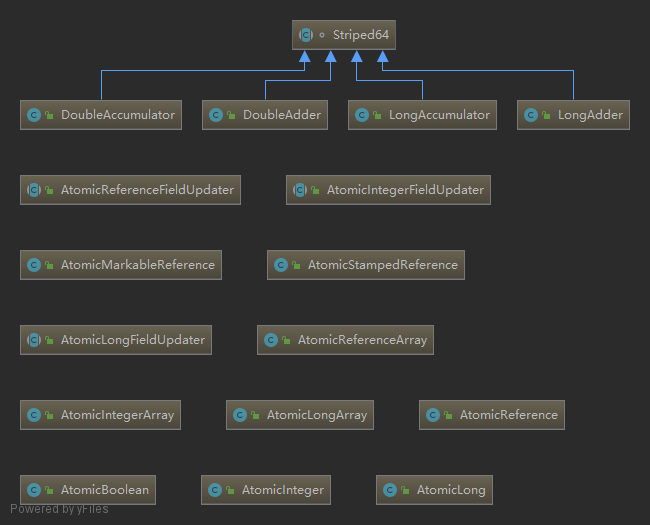
JDK 5 新增的原子类,底层基于魔术类 Unsafe 进行 CAS 无锁操作。实现类按功能分组如下:
| Integer | Long | Boolean | 引用类型 | |
|---|---|---|---|---|
| 基本类 | AtomicInteger |
AtomicLong |
AtomicBoolean |
|
| 引用类型 | AtomicReferenceAtomicStampedReferenceAtomicMarkableReference |
|||
| 数组类型 | AtomicIntegerArray |
AtomicLongArray |
AtomicReferenceArray |
|
| 属性原子修改器 | AtomicIntegerFieldUpdater |
AtomicLongFieldUpdater |
AtomicReferenceFieldUpdater |
JDK 8 新增 Striped64 累加计数器这个并发组件,64 指的是计数 64 bit 的数,即 Long 和 Double 类型。其实现类如下:
| Long | Double |
|---|---|
LongAdder |
DoubleAdder |
LongAccumulator |
DoubleAccumulator |
性能对比参考:http://www.manongjc.com/article/105666.html
Spring 包简介
Task Execution and Scheduling - Spring Framework
org.springframework.scheduling
Spring Framework 中并发编程相关的类主要位于 spring-context 下的 org.springframework.scheduling,例如其子包 concurrent:
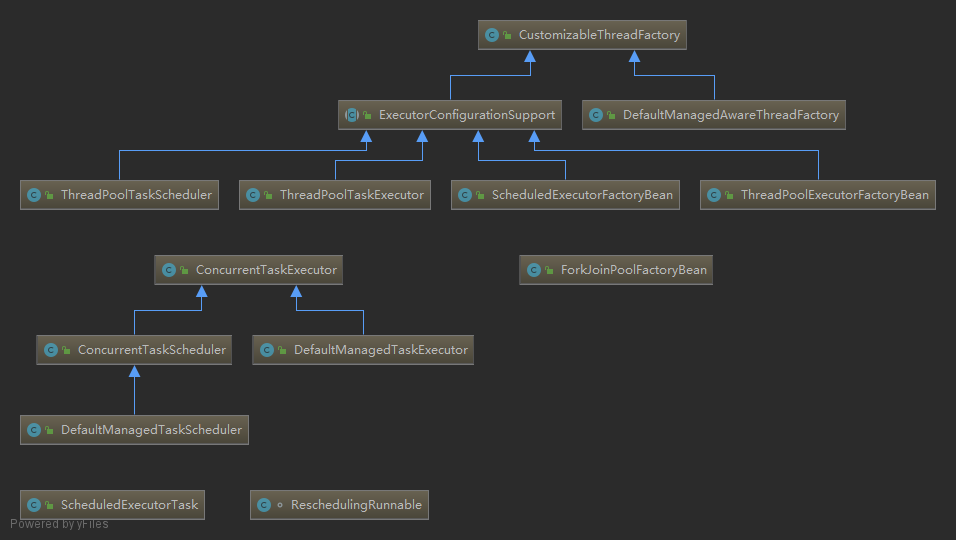
其中,顶层的 org.springframework.scheduling.concurrent.CustomizableThreadFactory 结构如下:
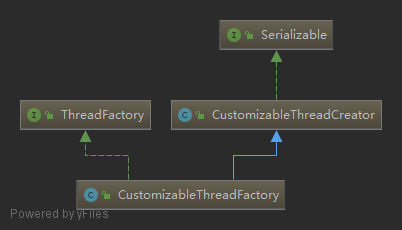
CustomizableThreadFactory实现了java.util.concurrent.ThreadFactory线程工厂接口,源码如下:1
2
3
4// Executors.defaultThreadFactory 方法提供了一个实用的简单实现,为新线程设置了上下文,详见源码
public interface ThreadFactory {
Thread newThread(Runnable r);
}CustomizableThreadFactory继承了org.springframework.util.CustomizableThreadCreator类,用于创建新线程,并提供各种线程属性自定义配置(如线程名前缀、线程优先级等)。
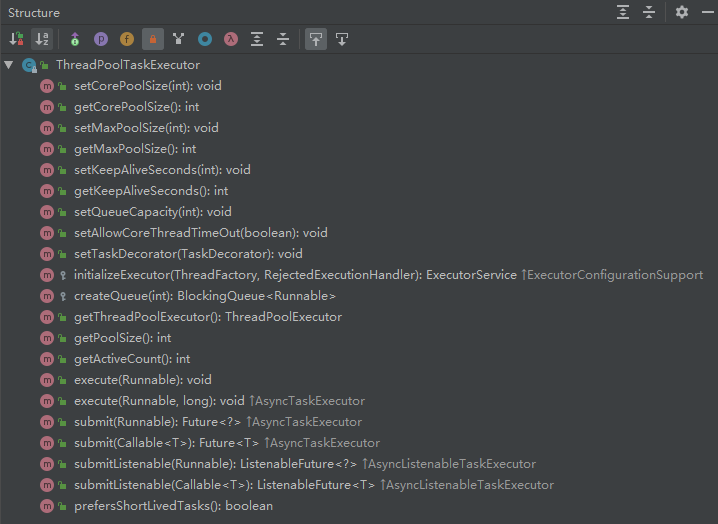
然后重点看下最常用的 org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor 类,提供的方法列表如下:
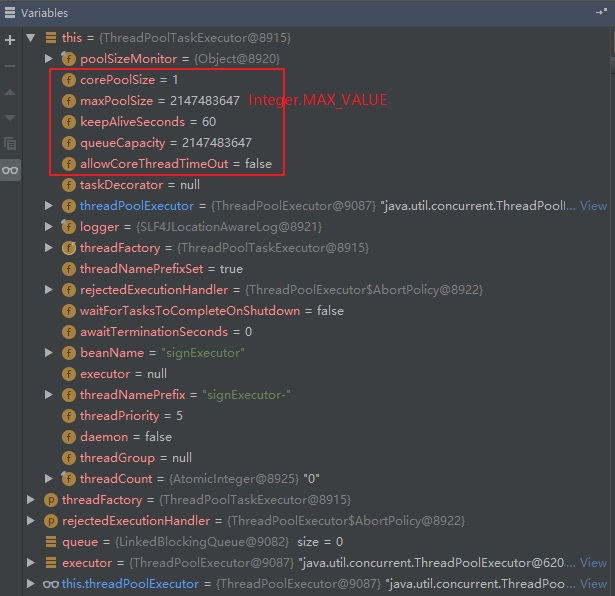
当我们在实例化 ThreadPoolTaskExecutor 对象之后,其变量如下:
其调用堆栈如下:

可见,实际上是先调用了抽象父类 ExecutorConfigurationSupport 的 afterPropertiesSet() 和 initialize() 方法,最后再调用 ThreadPoolTaskExecutor#initializeExecutor(...),该方法源码如下:
1 |
|
实际上就是通过构造方法实例化 java.util.concurrent.ThreadPoolExecutor 对象,并设置相应参数。